Intro
Removing duplicates from a dataset or a list is a crucial task in data processing and management. It helps in maintaining the integrity and uniqueness of the data, which is essential for various applications, including data analysis, reporting, and decision-making. In this article, we will explore five ways to remove duplicates, discussing the benefits, working mechanisms, and steps involved in each method.
The importance of removing duplicates cannot be overstated. Duplicate data can lead to inaccurate analysis, skewed results, and poor decision-making. For instance, in a customer database, duplicate entries can result in multiple mailings or offers being sent to the same customer, leading to wasted resources and a negative customer experience. Similarly, in data analysis, duplicate data can distort statistical results, making it challenging to draw meaningful conclusions.
In recent years, the proliferation of data has made it increasingly difficult to manage and maintain data quality. With the exponential growth of data from various sources, including social media, IoT devices, and sensors, the likelihood of duplicate data has increased significantly. Therefore, it is essential to have effective methods for removing duplicates to ensure data accuracy, completeness, and consistency.
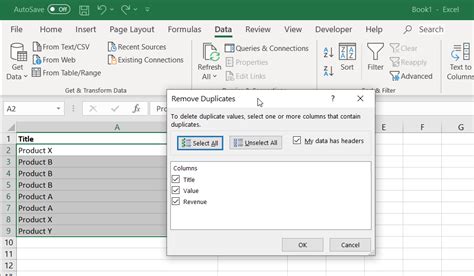
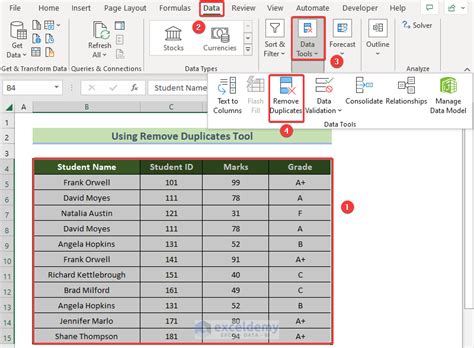
Method 1: Using Microsoft Excel
Method 2: Using SQL

Method 3: Using Python

Method 4: Using Data Cleaning Tools

Method 5: Using Manual Methods

Benefits of Removing Duplicates
Removing duplicates from a dataset or list has several benefits, including: * Improved data accuracy and quality * Reduced data redundancy and storage requirements * Enhanced data analysis and reporting * Better decision-making and insights * Increased efficiency and productivityCommon Challenges in Removing Duplicates
Removing duplicates can be challenging, especially when dealing with large datasets or complex data structures. Some common challenges include: * Identifying duplicate rows or entries * Handling missing or null values * Dealing with data inconsistencies and errors * Ensuring data integrity and consistency * Managing data storage and processing requirementsRemove Duplicates Image Gallery






What are the benefits of removing duplicates from a dataset?
+The benefits of removing duplicates from a dataset include improved data accuracy and quality, reduced data redundancy and storage requirements, enhanced data analysis and reporting, better decision-making and insights, and increased efficiency and productivity.
How can I remove duplicates from a dataset using Microsoft Excel?
+To remove duplicates from a dataset using Microsoft Excel, select the range of cells that contains the data, go to the "Data" tab in the ribbon, and click on "Remove Duplicates." Then, select the columns to use for identifying duplicates and click "OK" to remove the duplicates.
What are some common challenges in removing duplicates from a dataset?
+Some common challenges in removing duplicates from a dataset include identifying duplicate rows or entries, handling missing or null values, dealing with data inconsistencies and errors, ensuring data integrity and consistency, and managing data storage and processing requirements.
How can I remove duplicates from a dataset using Python?
+To remove duplicates from a dataset using Python, import the "pandas" library and load the dataset into a DataFrame. Then, use the "drop_duplicates" method to remove duplicate rows from the DataFrame, specifying the columns to use for identifying duplicates using the "subset" parameter.
What are some best practices for removing duplicates from a dataset?
+Some best practices for removing duplicates from a dataset include using automated tools and techniques, handling missing or null values, ensuring data integrity and consistency, managing data storage and processing requirements, and verifying the results of the duplicate removal process.
In conclusion, removing duplicates from a dataset or list is a critical task that requires careful consideration and attention to detail. By using the methods and techniques outlined in this article, you can effectively remove duplicates and improve the accuracy, quality, and reliability of your data. Whether you are working with Microsoft Excel, SQL, Python, or other tools and technologies, removing duplicates is an essential step in data processing and analysis. We hope this article has provided you with the knowledge and insights you need to remove duplicates and achieve your data management goals. If you have any further questions or comments, please do not hesitate to share them with us.