Intro
The concept of counting partial text has become increasingly important in various fields, including data analysis, natural language processing, and text mining. With the vast amount of text data available, it's crucial to develop efficient methods for counting and analyzing partial text. In this article, we will explore five ways to count partial text, highlighting their benefits, limitations, and applications.
Counting partial text involves identifying and quantifying specific patterns or substrings within a larger text. This can be useful for tasks such as sentiment analysis, topic modeling, and information retrieval. The five methods we will discuss are:
- String Matching: This method involves searching for exact matches of a given substring within a larger text.
- Regular Expressions: Regular expressions provide a powerful way to search for patterns in text data, allowing for flexible and efficient counting of partial text.
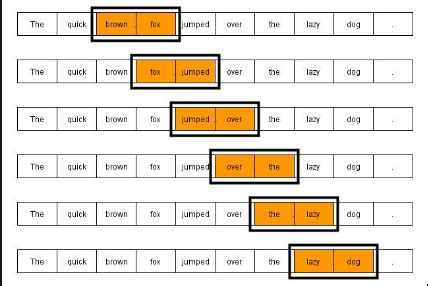
- Tokenization: Tokenization involves breaking down text into individual words or tokens, which can then be counted and analyzed.
- N-Grams: N-grams are a technique for counting sequences of n items in a text, providing a way to analyze patterns and relationships between words.
- Machine Learning: Machine learning algorithms can be trained to count and classify partial text, offering a high degree of accuracy and flexibility.
Introduction to String Matching
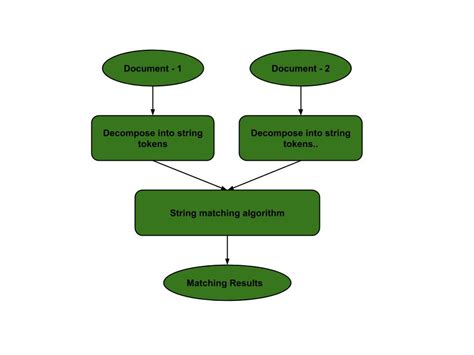
String matching is a straightforward approach to counting partial text. It involves searching for exact matches of a given substring within a larger text. This method is simple to implement and can be effective for counting short, well-defined patterns. However, it may not be suitable for longer or more complex patterns, as it can be computationally intensive and prone to errors.
Regular Expressions for Partial Text Counting

Regular expressions offer a more flexible and powerful approach to counting partial text. They provide a way to search for patterns in text data using a formal language, allowing for efficient and accurate counting of complex patterns. Regular expressions are widely used in text analysis and are supported by most programming languages.
Tokenization for Text Analysis
Tokenization involves breaking down text into individual words or tokens, which can then be counted and analyzed. This method is useful for tasks such as sentiment analysis and topic modeling, where the frequency and co-occurrence of words are important. Tokenization can be performed using various techniques, including rule-based approaches and machine learning algorithms.
N-Grams for Pattern Analysis

N-grams are a technique for counting sequences of n items in a text, providing a way to analyze patterns and relationships between words. This method is useful for tasks such as language modeling and text classification, where the context and sequence of words are important. N-grams can be used to count partial text, including phrases and sentences.
Machine Learning for Partial Text Counting
Machine learning algorithms can be trained to count and classify partial text, offering a high degree of accuracy and flexibility. This approach involves training a model on labeled data, where the model learns to recognize patterns and relationships between words. Machine learning is widely used in text analysis and can be applied to a variety of tasks, including sentiment analysis, topic modeling, and information retrieval.
Benefits and Limitations of Each Method
Each of the five methods has its benefits and limitations. String matching is simple to implement but may not be suitable for longer or more complex patterns. Regular expressions offer a high degree of flexibility and accuracy but can be computationally intensive. Tokenization is useful for tasks such as sentiment analysis and topic modeling but may not capture the context and sequence of words. N-grams provide a way to analyze patterns and relationships between words but may not be suitable for longer sequences. Machine learning offers a high degree of accuracy and flexibility but requires large amounts of labeled data and computational resources.
Applications and Future Directions
The five methods for counting partial text have a wide range of applications, including data analysis, natural language processing, and text mining. They can be used for tasks such as sentiment analysis, topic modeling, and information retrieval, and are widely used in industries such as marketing, finance, and healthcare. Future directions for research and development include improving the accuracy and efficiency of each method, as well as exploring new applications and domains.
Partial Text Counting Image Gallery



What is partial text counting?
+Partial text counting involves identifying and quantifying specific patterns or substrings within a larger text.
What are the benefits of using regular expressions for partial text counting?
+Regular expressions offer a high degree of flexibility and accuracy, allowing for efficient and accurate counting of complex patterns.
What is the difference between tokenization and n-grams?
+Tokenization involves breaking down text into individual words or tokens, while n-grams involve counting sequences of n items in a text.
In conclusion, the five methods for counting partial text offer a range of benefits and limitations, and can be applied to a variety of tasks and domains. By understanding the strengths and weaknesses of each method, researchers and practitioners can choose the most suitable approach for their specific needs. We invite readers to share their experiences and insights on partial text counting, and to explore the many applications and future directions of this important topic.