Intro
Discover 5 ways to highlight duplicates in datasets, leveraging data analysis, duplicate detection, and data cleansing techniques to improve data quality and accuracy, and streamline data management processes efficiently.
Highlighting duplicates in a dataset or a list is an essential task for data analysis, data cleaning, and ensuring data integrity. Duplicates can skew analysis results, lead to incorrect conclusions, and waste resources if not identified and handled properly. There are several methods and tools available to highlight duplicates, each with its own strengths and suitable applications. Here, we'll explore five ways to highlight duplicates, focusing on their methodologies, advantages, and typical use cases.
The ability to detect and manage duplicate data is critical in various fields, including business, research, and governance. Duplicates can arise from multiple sources, such as data entry errors, data migration issues, or the integration of data from different systems. Identifying these duplicates is the first step towards cleaning and normalizing a dataset, which is essential for reliable analysis and decision-making.
In many applications, especially those involving large datasets, manual detection of duplicates is impractical and prone to errors. Therefore, leveraging automated methods and tools is not only efficient but also necessary. These methods can range from simple algorithms that compare rows in a spreadsheet to complex data processing pipelines that utilize machine learning for duplicate detection.
Understanding Duplicate Data
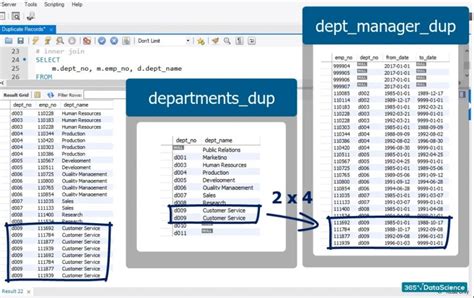
Before diving into the methods for highlighting duplicates, it's crucial to understand what constitutes duplicate data. Duplicate data refers to multiple records or entries that contain the same information, either partially or entirely. The duplication can occur in a single dataset or across different datasets. Identifying duplicates requires a clear definition of what makes two records identical, which can vary depending on the context and the specific requirements of the analysis or application.
Method 1: Using Spreadsheet Functions
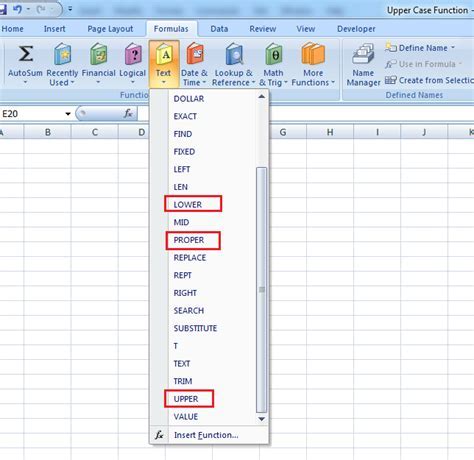
One of the most straightforward ways to highlight duplicates in a dataset is by using spreadsheet functions. Most spreadsheet software, such as Microsoft Excel or Google Sheets, offers built-in functions like COUNTIF, IF, and conditional formatting that can help identify duplicate entries. For example, the COUNTIF function can count the occurrences of each value in a column, and conditional formatting can highlight cells that appear more than once. This method is simple, effective for small to medium-sized datasets, and does not require advanced technical skills.
Advantages and Use Cases
- Ease of Use: Spreadsheet functions are widely available and easy to use, making them accessible to a broad range of users.
- Flexibility: These functions can be combined in various ways to suit different types of data and duplication criteria.
- Real-Time Feedback: Changes in the dataset are reflected immediately, allowing for dynamic analysis and adjustment.
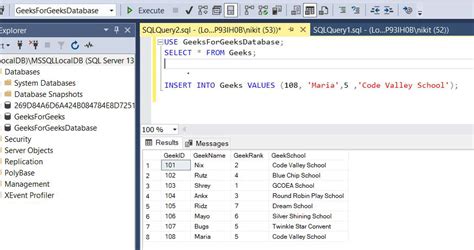
Method 2: Utilizing Database Queries

For larger datasets or in environments where data is stored in databases, using database queries (e.g., SQL) is an efficient way to identify duplicates. SQL commands like SELECT, GROUP BY, and HAVING can be used to find duplicate rows based on one or more columns. This method is particularly useful in scenarios where data is too large for spreadsheet analysis or when the data is already stored in a database management system.
Benefits and Applications
- Scalability: Database queries can handle large volumes of data efficiently, making them ideal for big data analysis.
- Precision: Queries can be tailored to identify duplicates based on specific conditions, reducing false positives.
- Integration: Since many applications interact with databases, using database queries for duplicate detection can be seamlessly integrated into existing workflows.
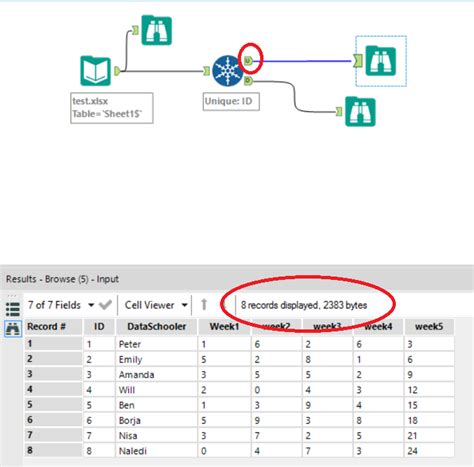
Method 3: Employing Data Analysis Software

Specialized data analysis software, such as pandas in Python or R, offers powerful libraries and functions designed specifically for data manipulation and analysis, including duplicate detection. These tools provide more advanced features than spreadsheet functions or database queries, such as handling missing data, performing fuzzy matching, and integrating with other data science tasks.
Key Features and Use Cases
- Advanced Duplicate Detection: Capabilities like fuzzy matching and similarity measures can identify duplicates that are not exact but very similar.
- Data Cleaning: Integrated functions for handling missing data, data normalization, and data transformation make these tools comprehensive solutions for data preparation.
- Customization: Users can write custom scripts to tailor the duplicate detection process to their specific needs, including complex logic and conditions.
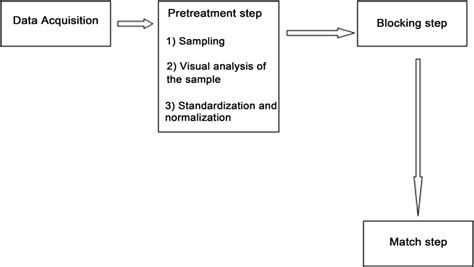
Method 4: Leveraging Machine Learning Algorithms
Machine learning algorithms can be trained to identify duplicates based on patterns in the data. This approach is particularly useful for detecting duplicates in unstructured or semi-structured data, such as text documents or images, where traditional methods may fail. Techniques like clustering, classification, and deep learning can be applied to recognize similar entities across different datasets.
Advantages and Applications
- Handling Complex Data: Machine learning can deal with complex, high-dimensional data where manual or rule-based approaches are impractical.
- High Accuracy: Trained models can achieve high accuracy in duplicate detection, especially when the training data is representative and of good quality.
- Scalability and Efficiency: Once trained, models can process large datasets quickly, making them suitable for real-time applications.
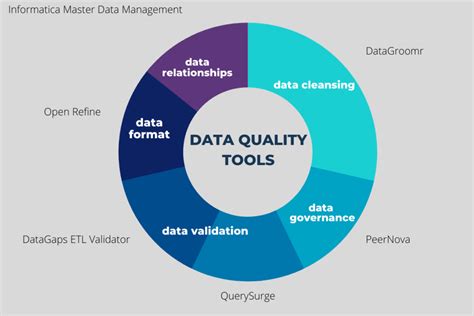
Method 5: Using Dedicated Data Quality Tools

Dedicated data quality tools and platforms are designed to manage and improve data quality, including duplicate detection. These tools often provide a user-friendly interface, automated workflows, and advanced algorithms for identifying and resolving duplicates. They can connect to various data sources, handle large datasets, and offer features like data profiling, data standardization, and data matching.
Benefits and Use Cases
- Comprehensive Data Quality Management: These tools offer a holistic approach to data quality, including duplicate detection, data validation, and data enhancement.
- Ease of Use: Designed for data stewards and business users, these platforms provide an intuitive interface that simplifies complex data quality tasks.
- Integration and Scalability: They can integrate with existing data infrastructure and scale to meet the needs of growing datasets and complex data environments.
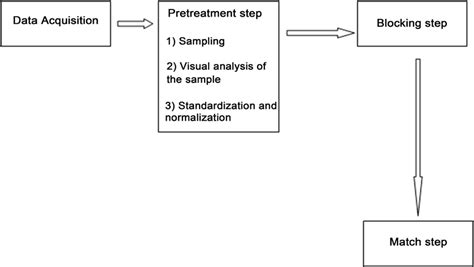
Gallery of Duplicate Detection Methods
Duplicate Detection Image Gallery
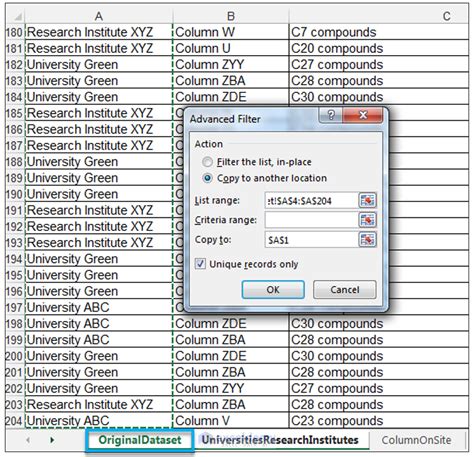



Frequently Asked Questions
What are the consequences of not removing duplicates from a dataset?
+Not removing duplicates can lead to biased analysis, incorrect conclusions, and inefficient use of resources. It can also affect the accuracy of machine learning models and other data-driven applications.
How do I choose the best method for detecting duplicates in my dataset?
+The choice of method depends on the size of the dataset, the complexity of the data, the available tools and expertise, and the specific requirements of the project. For small datasets, spreadsheet functions might suffice, while larger datasets may require database queries or dedicated data quality tools.
Can machine learning algorithms always detect duplicates accurately?
+While machine learning algorithms can achieve high accuracy in duplicate detection, their performance depends on the quality of the training data, the complexity of the duplicates, and the chosen algorithm. They may not always detect duplicates with 100% accuracy, especially in cases of fuzzy or approximate duplicates.
In conclusion, highlighting duplicates is a critical step in data preparation and analysis, ensuring the integrity and reliability of the data. The choice of method depends on various factors, including the size and complexity of the dataset, the available tools, and the specific goals of the analysis. By understanding the different approaches to duplicate detection and selecting the most appropriate method, data analysts and scientists can improve the quality of their data, reduce errors, and enhance the outcomes of their analyses. Whether through simple spreadsheet functions, advanced machine learning algorithms, or dedicated data quality tools, effective duplicate detection is essential for making informed decisions in today's data-driven world. We invite readers to share their experiences with duplicate detection, ask questions, and explore the wealth of information available on this critical topic.