Intro
Discover 5 ways to remove prefix from strings, tables, and columns, using techniques like substring, replace, and regex, to simplify data manipulation and improve database organization with efficient prefix removal methods.
Removing prefixes from words can be a crucial step in various linguistic and computational tasks, such as text processing, data cleaning, and natural language understanding. Prefixes are morphemes that are added to the beginning of a word to modify its meaning. The process of removing them can help in extracting roots or base words, which is essential for tasks like stemming or lemmatization in information retrieval and text analysis. Here are five ways to remove prefixes, each with its own approach and application:
The importance of understanding and manipulating prefixes lies in their ability to change the meaning of words significantly. For instance, the prefix "un-" can negate the meaning of a word, as seen in "unhappy" versus "happy". Being able to programmatically or manually remove such prefixes can aid in understanding the core meaning of words and their relationships. This is particularly useful in applications like sentiment analysis, where the removal of prefixes can help in identifying the base sentiment of a word.
Given the complexity and variability of languages, especially English, which borrows words from numerous other languages, the rules for removing prefixes can be quite nuanced. However, there are general approaches and tools that can be employed to achieve this. Whether it's through manual analysis, using predefined dictionaries, or leveraging machine learning algorithms, the goal remains to accurately identify and remove prefixes to uncover the root words.
Understanding Prefixes
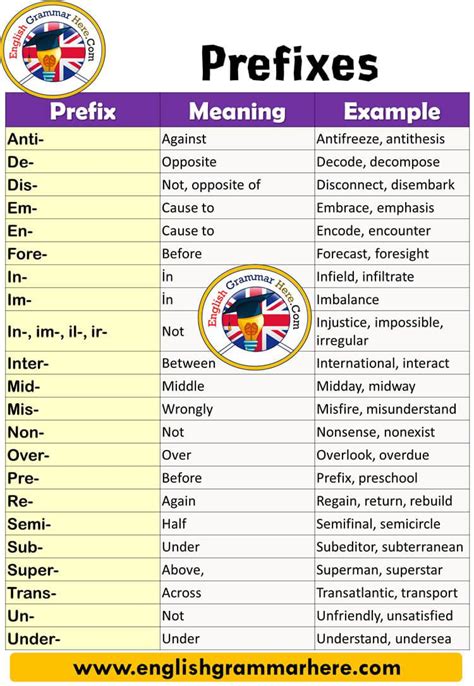
Before diving into the methods of removing prefixes, it's essential to understand what prefixes are and how they function within the structure of a word. Prefixes are one of the three main types of affixes, the other two being suffixes and infixes. While suffixes are added to the end of a word and infixes are inserted within a word, prefixes are added to the beginning. The function of a prefix can vary greatly, from indicating negation (e.g., "un-") to showing location (e.g., "sub-"), time (e.g., "post-"), or manner (e.g., "co-").
Manual Removal

Manual removal of prefixes involves identifying and removing the prefix from a word based on linguistic knowledge or predefined rules. This method can be time-consuming and is typically used for small datasets or when high precision is required. It involves understanding the meaning and function of different prefixes and applying this knowledge to remove them correctly. For example, recognizing that "un-" is a prefix of negation, one can manually remove it from words like "unhappy" to get "happy".
Steps for Manual Removal
- Identify the word from which the prefix is to be removed. - Determine the prefix of the word based on linguistic rules or a dictionary. - Remove the identified prefix from the word. - Verify that the resulting word is valid and makes sense in the context.Using Dictionaries and Lexical Resources

Another approach to removing prefixes is by using dictionaries or lexical resources that list words along with their prefixes and roots. This method is more systematic and can be applied to larger datasets. Dictionaries can provide a list of prefixes and their meanings, which can then be used to identify and remove prefixes from words. Additionally, some lexical resources may include algorithms or tools that can automatically remove prefixes based on predefined rules.
Benefits of Lexical Resources
- Provide a comprehensive list of prefixes and their meanings. - Can be used to validate the removal of prefixes. - Often include tools or algorithms for automatic prefix removal.Leveraging Machine Learning

Machine learning offers a powerful approach to removing prefixes by training models on large datasets of words and their corresponding roots. This method can learn patterns and rules automatically, making it highly effective for large-scale text processing tasks. Models can be trained to recognize prefixes based on their linguistic features and the context in which they appear, allowing for accurate removal of prefixes from a wide range of words.
Machine Learning Steps
- Collect a large dataset of words with their prefixes and roots. - Preprocess the data to extract relevant features. - Train a machine learning model on the dataset. - Use the trained model to predict and remove prefixes from new, unseen words.Regular Expressions
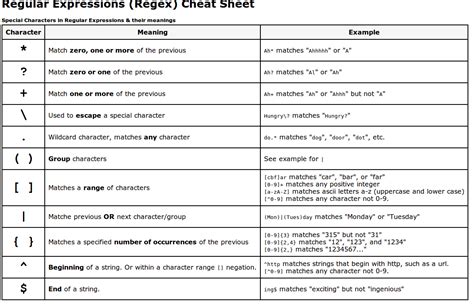
Regular expressions (regex) provide a programming approach to removing prefixes by defining patterns that match prefixes and then replacing them. This method is highly flexible and can be used in various programming languages. By crafting regex patterns that match known prefixes, developers can write scripts to automatically remove these prefixes from words in a dataset.
Regex Pattern Example
- The pattern "^un" can be used to match words that start with the prefix "un". - Using regex functions, this prefix can then be removed from the words.Natural Language Processing (NLP) Tools
NLP tools and libraries, such as NLTK, spaCy, or Stanford CoreNLP, offer pre-built functions and models for morphological analysis, including the removal of prefixes. These tools can analyze words to identify and separate prefixes, providing a convenient and efficient way to process large amounts of text. They often include dictionaries, lexical resources, and machine learning models that have been trained on extensive datasets, making them highly accurate.
NLP Tools Benefits
- Provide pre-built functions for prefix removal. - Often include large lexical resources and datasets. - Can be integrated into various applications for text analysis.Prefix Removal Image Gallery




What is the purpose of removing prefixes from words?
+The purpose of removing prefixes is to extract the root or base word, which can be useful in text analysis, sentiment analysis, and information retrieval tasks.
How can prefixes be removed manually?
+Prefixes can be removed manually by identifying the prefix based on linguistic rules or dictionaries and then removing it from the word.
What tools can be used for automatic prefix removal?
+NLP tools and libraries, such as NLTK, spaCy, or Stanford CoreNLP, provide functions and models for morphological analysis, including prefix removal.
In conclusion, the removal of prefixes from words is a crucial task in natural language processing and text analysis. Whether through manual analysis, the use of dictionaries and lexical resources, machine learning, regular expressions, or NLP tools, each method has its own strengths and applications. By understanding the different approaches to prefix removal, individuals and organizations can better process and analyze text data, unlocking deeper insights and improving the efficacy of their applications. We invite readers to share their experiences and questions regarding prefix removal and its applications in the comments below, and to explore further the vast potential of natural language processing in enhancing our interaction with and understanding of text.