Intro
Discover 5 ways to compare rows in tables, spreadsheets, and databases, using data comparison tools and techniques for efficient data analysis, row matching, and duplicate detection, with tips on data merging and row synchronization.
Comparing rows in a dataset is a fundamental task in data analysis, allowing researchers and analysts to identify patterns, trends, and correlations. With the advent of advanced computational tools and programming languages like Python and R, comparing rows has become more efficient and accurate. Here, we will delve into five ways to compare rows, exploring their methodologies, applications, and benefits.
The importance of comparing rows cannot be overstated, as it enables the identification of duplicate records, data inconsistencies, and outliers. By analyzing rows, researchers can gain insights into the underlying structure of the data, which is crucial for making informed decisions. Whether it's in the context of business intelligence, scientific research, or social sciences, comparing rows is an indispensable step in the data analysis process.
In many cases, comparing rows involves examining the values in each column for a given set of rows. This can be done manually for small datasets, but as the size of the dataset increases, manual comparison becomes impractical. Fortunately, various algorithms and techniques have been developed to facilitate the comparison of rows, including hashing, sorting, and clustering. These methods can be applied to different types of data, including numerical, categorical, and text data.
Method 1: Hashing
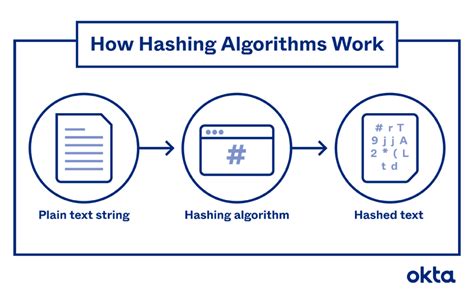
Hashing is a widely used technique for comparing rows, particularly in large datasets. The basic idea behind hashing is to assign a unique numerical value, known as a hash value, to each row based on its contents. By comparing the hash values of different rows, researchers can quickly identify identical or similar rows. Hashing is efficient because it allows for fast lookup and comparison of rows, making it an ideal approach for big data applications.
One of the key benefits of hashing is its ability to handle high-dimensional data. In many cases, datasets contain a large number of columns, making it challenging to compare rows using traditional methods. Hashing overcomes this limitation by reducing the dimensionality of the data, enabling researchers to focus on the most important features. Furthermore, hashing can be used in conjunction with other techniques, such as clustering and dimensionality reduction, to gain a deeper understanding of the data.
Method 2: Sorting
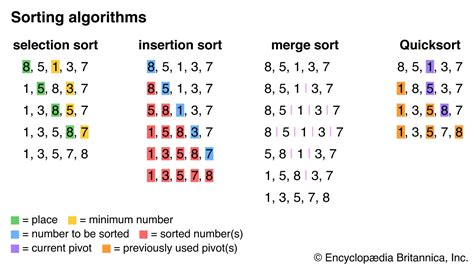
Sorting is another effective method for comparing rows, particularly when dealing with numerical or categorical data. The basic idea behind sorting is to arrange the rows in a specific order, such as ascending or descending, based on one or more columns. By sorting the rows, researchers can easily identify similar or identical rows, as well as outliers and anomalies.
One of the advantages of sorting is its simplicity and ease of implementation. Sorting algorithms are widely available in programming languages like Python and R, making it a straightforward task to sort and compare rows. Additionally, sorting can be used in conjunction with other techniques, such as hashing and clustering, to gain a more comprehensive understanding of the data.
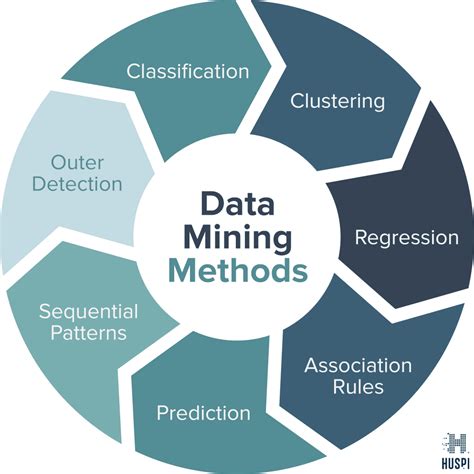
Method 3: Clustering
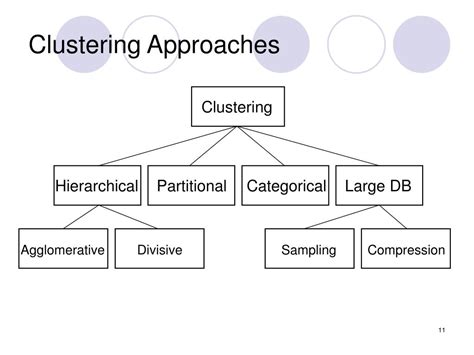
Clustering is a powerful technique for comparing rows, particularly when dealing with complex datasets. The basic idea behind clustering is to group similar rows together based on their characteristics, such as values or patterns. By clustering rows, researchers can identify underlying structures and relationships in the data, which can be used to inform decision-making.
One of the benefits of clustering is its ability to handle high-dimensional data. Clustering algorithms can reduce the dimensionality of the data, enabling researchers to focus on the most important features. Additionally, clustering can be used in conjunction with other techniques, such as hashing and sorting, to gain a more comprehensive understanding of the data.
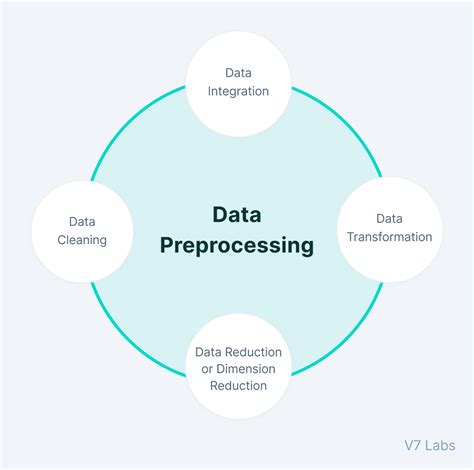
Method 4: Dimensionality Reduction
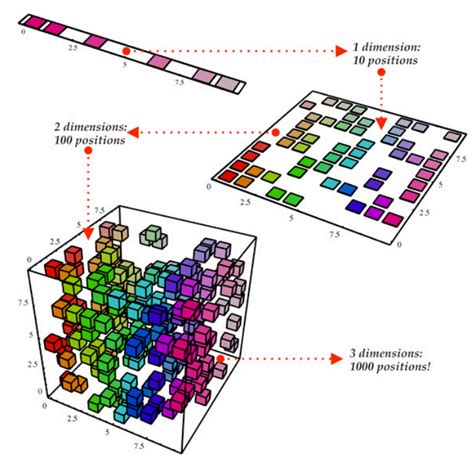
Dimensionality reduction is a technique used to reduce the number of columns or features in a dataset, making it easier to compare rows. The basic idea behind dimensionality reduction is to select the most important features or columns, while discarding the less important ones. By reducing the dimensionality of the data, researchers can gain a better understanding of the underlying structures and relationships.
One of the advantages of dimensionality reduction is its ability to improve the accuracy of comparison methods. By reducing the number of features, researchers can reduce the risk of overfitting and improve the generalizability of the results. Additionally, dimensionality reduction can be used in conjunction with other techniques, such as hashing and clustering, to gain a more comprehensive understanding of the data.
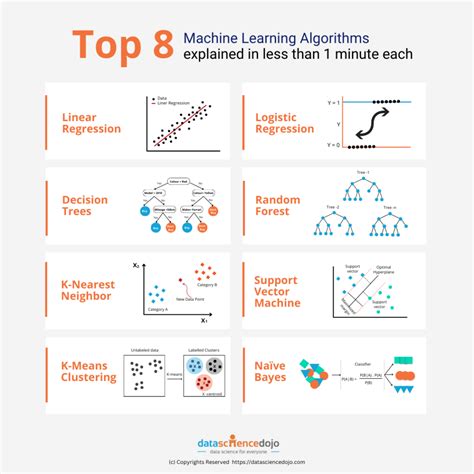
Method 5: Machine Learning

Machine learning is a powerful technique for comparing rows, particularly when dealing with complex datasets. The basic idea behind machine learning is to train a model on a labeled dataset, enabling it to learn patterns and relationships in the data. By applying the trained model to new, unseen data, researchers can compare rows and make predictions or classifications.
One of the benefits of machine learning is its ability to handle high-dimensional data. Machine learning algorithms can learn complex patterns and relationships in the data, enabling researchers to gain a deeper understanding of the underlying structures. Additionally, machine learning can be used in conjunction with other techniques, such as hashing and clustering, to gain a more comprehensive understanding of the data.
Gallery of Row Comparison Methods
Row Comparison Methods Image Gallery

What is the purpose of comparing rows in a dataset?
+The purpose of comparing rows in a dataset is to identify patterns, trends, and correlations, as well as to detect duplicate records, data inconsistencies, and outliers.
What are the benefits of using hashing for row comparison?
+The benefits of using hashing for row comparison include fast lookup and comparison of rows, ability to handle high-dimensional data, and improved accuracy of comparison methods.
What is the difference between sorting and clustering for row comparison?
+Sorting involves arranging rows in a specific order based on one or more columns, while clustering involves grouping similar rows together based on their characteristics.
What is the role of machine learning in row comparison?
+Machine learning plays a crucial role in row comparison by enabling the training of models on labeled datasets, which can then be applied to new, unseen data to make predictions or classifications.
What are the applications of row comparison in real-world scenarios?
+The applications of row comparison include data analysis, business intelligence, scientific research, and social sciences, among others.
In conclusion, comparing rows is a crucial step in data analysis, enabling researchers to identify patterns, trends, and correlations, as well as to detect duplicate records, data inconsistencies, and outliers. By using techniques such as hashing, sorting, clustering, dimensionality reduction, and machine learning, researchers can gain a deeper understanding of the underlying structures and relationships in the data. We hope this article has provided valuable insights into the world of row comparison, and we encourage readers to share their thoughts and experiences in the comments below. Whether you're a seasoned data analyst or just starting out, we invite you to explore the various methods and techniques discussed in this article and to apply them to your own research and projects.