Intro
Learn 5 ways to remove unwanted characters, including special chars, from text using efficient methods and tools, simplifying data cleaning and text editing processes with character removal techniques.
The importance of removing unwanted characters from text cannot be overstated, especially in the digital age where data cleanliness is crucial for analysis, processing, and presentation. Characters can be anything from letters, numbers, and symbols to whitespace and punctuation marks. Unwanted characters can find their way into datasets, documents, and even code through various means, such as data entry errors, copying and pasting from different sources, or through automated processes that fail to filter out unnecessary characters. Removing these characters is essential for ensuring data integrity, readability, and compatibility across different systems and applications.
The process of removing characters can vary significantly depending on the context and the tools available. For instance, in text editing and word processing, users often need to remove unwanted characters to clean up a document or to prepare text for further processing. In programming and data analysis, removing characters is a common step in data preprocessing to ensure that datasets are consistent and free of errors. The methods for removing characters can range from manual deletion, which is time-consuming and prone to errors, to automated scripts and functions that can efficiently process large amounts of text.
Removing unwanted characters is not just about cleaning up text; it also involves understanding the purpose of the text and the requirements of the application or system it will be used in. For example, in web development, removing special characters from user input can be crucial for preventing SQL injection attacks and ensuring website security. Similarly, in data science, cleaning text data by removing punctuation, converting all text to lowercase, and removing stop words can significantly improve the accuracy of text analysis models. Whether it's for security, data analysis, or simply to improve readability, the ability to efficiently remove unwanted characters is a valuable skill in today's digital landscape.
Understanding the Need for Character Removal

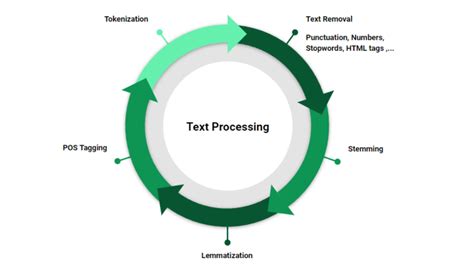
The need for character removal stems from the variety of sources from which text data can originate and the diverse purposes it can serve. Text can come from user inputs, databases, files, and web scraping, among other sources, each with its own set of potential issues such as encoding problems, formatting inconsistencies, and the presence of unwanted characters. Furthermore, the intended use of the text, whether it's for analysis, display, or processing, dictates the level and type of cleaning required. For instance, text meant for natural language processing (NLP) tasks may require the removal of stop words, stemming or lemmatization, and the handling of out-of-vocabulary words, whereas text for display purposes might only need the removal of special characters and formatting adjustments.
Methods for Removing Characters
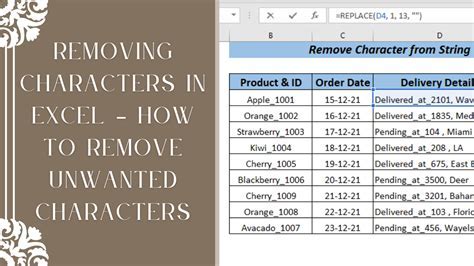
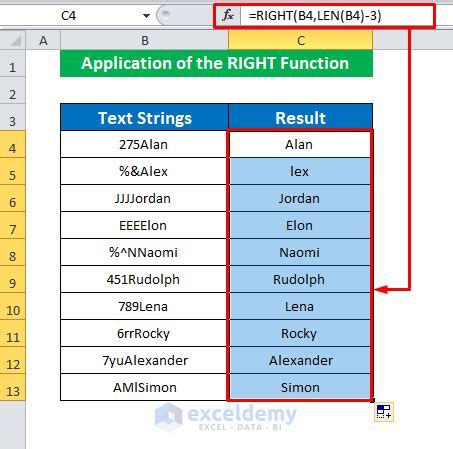
There are several methods for removing characters, each suited to different contexts and requirements. Manual removal is the most straightforward but least efficient method, involving the direct editing of text to delete unwanted characters. This method is feasible only for small amounts of text and is highly prone to human error. For larger datasets or more complex requirements, automated methods are preferable. These can include using regular expressions (regex) in programming languages like Python or JavaScript to match and replace patterns of characters. Another approach is using built-in functions in text editing software or programming libraries that offer text cleaning capabilities, such as the re module in Python or the stringr package in R.
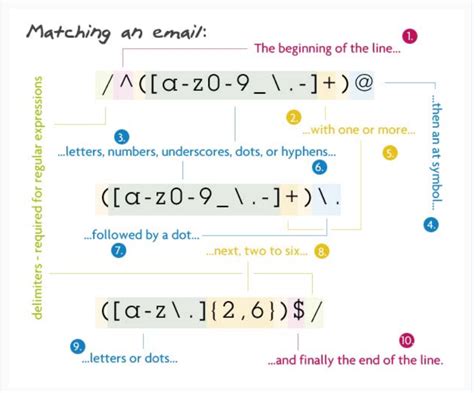
Regular Expressions for Character Removal
Regular expressions are a powerful tool for removing characters because they allow for the specification of complex patterns to match against. For example, to remove all punctuation from a string, a regex pattern like `[^\w\s]` can be used, which matches any character that is not a word character or whitespace. The versatility of regex makes it applicable to a wide range of character removal tasks, from simple cases like removing all digits or letters to more complex scenarios involving conditional matching based on character context.Tools and Software for Character Removal
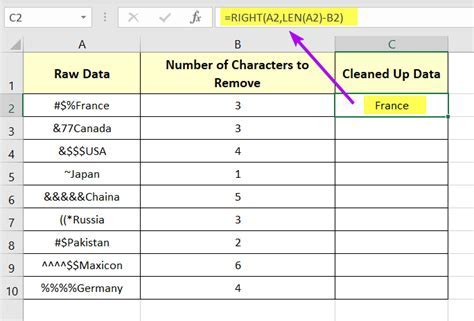
Several tools and software are available for removing characters, catering to different user needs and skill levels. Text editors like Notepad++, Sublime Text, and Visual Studio Code offer robust find and replace functionalities, including support for regex, making them versatile tools for character removal. For more specialized tasks, especially those involving large datasets, programming languages and their associated libraries are indispensable. Python, with its extensive range of libraries including pandas for data manipulation and re for regex operations, is particularly popular for text processing tasks. Similarly, R, with packages like stringr and tidytext, provides comprehensive capabilities for text cleaning and analysis.
Automating Character Removal with Scripts
Automating the process of character removal through scripts is highly beneficial for tasks that need to be repeated over time or applied to large volumes of data. Scripts can be written in various programming languages and can range from simple batch files that perform basic text replacement to complex scripts that integrate multiple cleaning steps and handle different types of input files. The key advantage of automation is efficiency; once a script is developed and tested, it can process data much faster and with fewer errors than manual methods.Best Practices for Character Removal
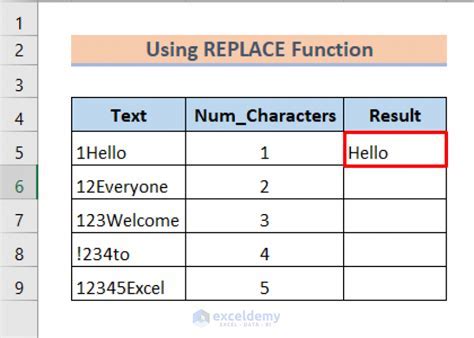
When removing characters, several best practices can ensure the process is effective and minimizes potential issues. First, it's crucial to understand the requirements of the task, including the type of characters to be removed and the desired outcome. Backup copies of the original data should always be made before initiating any cleaning process to prevent loss of information. Testing the removal process on a small sample of data is also advisable to ensure that the method used does not inadvertently remove needed characters or introduce other problems. Finally, validating the cleaned data against the original to check for any discrepancies or errors is an essential step in ensuring data quality.
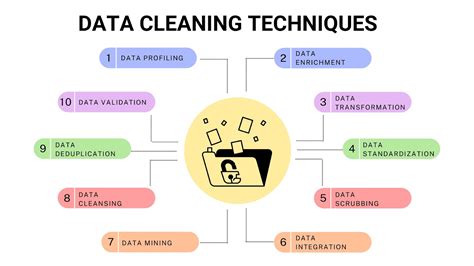
Common Challenges in Character Removal
Despite the availability of various tools and methods, character removal can pose several challenges. One of the most common issues is the risk of removing necessary characters, which can alter the meaning or functionality of the text. This risk is particularly high when using automated methods without properly testing them. Another challenge is dealing with encoding issues, where characters may not be recognized or processed correctly due to differences in character encoding schemes. Handling such challenges requires a combination of technical knowledge, attention to detail, and a systematic approach to testing and validation.Gallery of Character Removal Techniques
Character Removal Techniques Image Gallery




Frequently Asked Questions
What is the importance of removing unwanted characters from text?
+Removing unwanted characters is crucial for ensuring data integrity, readability, and compatibility across different systems and applications. It helps in preventing errors, improving data analysis, and enhancing the overall quality of the text.
How can regular expressions be used for character removal?
+Regular expressions can be used to specify patterns of characters to match and remove. They offer a flexible and powerful way to handle complex character removal tasks, including removing punctuation, digits, or specific sequences of characters.
What tools and software are available for character removal?
+A variety of tools and software are available, including text editors like Notepad++ and Sublime Text, programming languages like Python and R, and specialized data cleaning tools. The choice of tool depends on the specific requirements of the task, including the volume of data and the complexity of the removal process.
In conclusion, removing unwanted characters from text is a critical step in data preprocessing that can significantly impact the quality and usability of the data. By understanding the importance of character removal, being familiar with the methods and tools available, and following best practices, individuals can efficiently clean their text data and prepare it for various applications. Whether for data analysis, text processing, or simply to improve readability, the ability to remove unwanted characters is a valuable skill in today's data-driven world. We invite readers to share their experiences and tips on character removal, and to explore the resources provided for further learning and application.