Intro
Extract text easily with 5 simple methods, using OCR tools, copy paste, and more, to convert images and documents into editable text, boosting productivity and efficiency in data extraction and management tasks.
Extracting text from various sources is a common task in today's digital age. With the advancement of technology, there are multiple ways to extract text, each with its own unique benefits and applications. In this article, we will delve into five ways to extract text, exploring their methods, advantages, and uses.
The importance of text extraction cannot be overstated. It is a crucial step in data analysis, allowing users to gather and process information from a wide range of sources, including documents, images, and web pages. Whether you are a researcher, a student, or a professional, being able to extract text efficiently can save you time and effort, enabling you to focus on more critical tasks.
Text extraction has numerous applications across different fields. In academia, it is used for research purposes, such as extracting quotes or data from papers and books. In business, it can be used to gather information from reports, contracts, and other documents. Moreover, with the rise of digital media, text extraction from images and videos has become increasingly important for tasks like captioning and subtitling.
Introduction to Text Extraction Methods
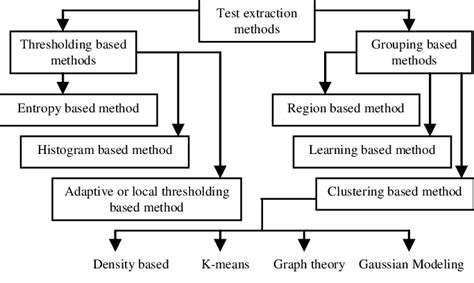
There are several methods to extract text, ranging from manual entry to automated processes using software and artificial intelligence. Each method has its own set of advantages and disadvantages, depending on the context and the nature of the source material. Understanding these methods is essential for choosing the most appropriate technique for a given task.
Manual Text Extraction

Manual text extraction involves typing out the text from a source document or image. This method is time-consuming and labor-intensive but can be highly accurate, especially when dealing with complex or distorted texts that automated systems may struggle to recognize. However, it is prone to human error and is not feasible for large volumes of text.
Benefits and Limitations of Manual Extraction
- Accuracy: Manual extraction can offer high accuracy, especially for texts that are not easily recognizable by machines.
- Flexibility: It can be applied to any type of text, regardless of the format or quality.
- Limitations: It is extremely time-consuming and can be costly, especially for large projects.
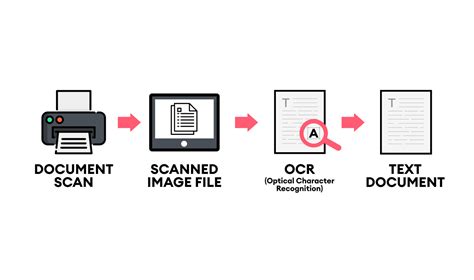
Optical Character Recognition (OCR)

Optical Character Recognition (OCR) is a technology that enables the conversion of images of text into editable text. OCR software can process scanned documents, photographs of text, and even text within images, making it a powerful tool for text extraction. The accuracy of OCR depends on the quality of the source image and the sophistication of the software used.
How OCR Works
- Image Acquisition: The first step involves capturing an image of the text. This can be done using a scanner or a camera.
- Pre-processing: The image is then enhanced to improve its quality. This may involve adjusting the brightness, removing noise, and correcting skew.
- Text Recognition: The pre-processed image is then analyzed by the OCR software, which identifies the text within the image.
- Post-processing: The recognized text may undergo further processing to correct errors and improve accuracy.
Automated Text Extraction Software
Automated text extraction software utilizes algorithms and artificial intelligence to extract text from digital sources, such as PDFs, emails, and web pages. These tools can process large volumes of data quickly and efficiently, making them ideal for businesses and organizations that need to extract text on a large scale.
Features of Automated Software
- Speed: Automated software can extract text much faster than manual methods.
- Volume: It can handle large volumes of data with ease.
- Accuracy: While generally high, the accuracy can depend on the software's sophistication and the quality of the source material.
Web Scraping
Web scraping involves using software or algorithms to extract data from websites. This method is particularly useful for gathering information from public sources, such as news articles, social media, and online databases. However, web scraping must be done responsibly and in accordance with the terms of service of the websites being scraped.
Legal and Ethical Considerations
- Terms of Service: Always check a website's terms of service before scraping its data.
- Privacy: Be mindful of privacy laws and regulations, especially when dealing with personal data.
- Responsible Scraping: Avoid overwhelming websites with too many requests, as this can be considered a denial-of-service attack.
Machine Learning and AI
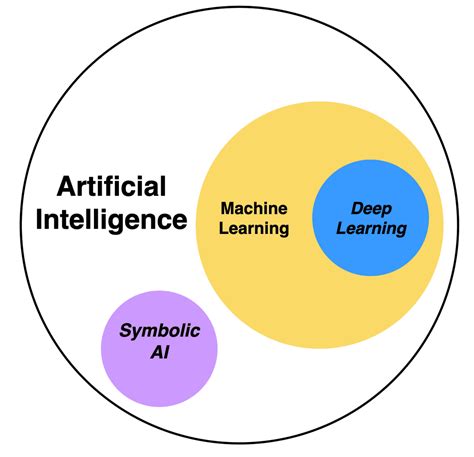
Machine learning and artificial intelligence (AI) are increasingly being used for text extraction, especially in complex scenarios such as extracting text from handwritten documents or videos. These technologies can learn patterns and improve their accuracy over time, making them highly effective for tasks that require a high degree of precision.
Applications of ML and AI in Text Extraction
- Handwritten Text Recognition: ML and AI can be used to recognize and extract handwritten text, which is challenging for traditional OCR systems.
- Video and Audio Transcription: These technologies can transcribe text from videos and audios, enabling the extraction of spoken words.
Text Extraction Image Gallery




What is the most accurate method of text extraction?
+The most accurate method of text extraction depends on the source material. For digital sources, automated software can be very accurate. However, for handwritten or distorted texts, manual extraction or advanced OCR systems may offer better results.
How does OCR technology improve text extraction?
+OCR technology improves text extraction by enabling the conversion of images of text into editable text. This makes it possible to extract text from scanned documents, photographs, and other image sources, greatly expanding the range of materials from which text can be extracted.
What are the ethical considerations of web scraping?
+Web scraping must be done ethically and legally. This includes respecting the terms of service of the websites being scraped, not overwhelming the website with requests, and being mindful of privacy laws and regulations, especially when dealing with personal data.
In conclusion, text extraction is a vital process in today's information age, with applications across various fields. The choice of method depends on the nature of the source material, the desired level of accuracy, and the volume of text to be extracted. As technology continues to evolve, we can expect even more efficient and accurate methods of text extraction to emerge. Whether you are a professional, a researcher, or simply someone looking to extract text for personal use, understanding the different methods available can help you achieve your goals more effectively. We invite you to share your experiences with text extraction, ask questions, or suggest topics for future discussions in the comments below.