Intro
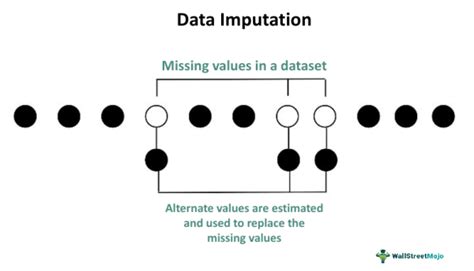
The importance of handling blank cells in datasets cannot be overstated. Blank cells can lead to inaccuracies in analysis, disrupt data visualization, and even cause errors in statistical models. Therefore, it is crucial to fill these blank cells with appropriate values to ensure the integrity and reliability of the data. In this article, we will delve into the various methods of filling blank cells, exploring their applications, benefits, and potential drawbacks.
Filling blank cells is a common task in data preprocessing, and it requires careful consideration to avoid introducing biases or inaccuracies into the dataset. The choice of method depends on the nature of the data, the cause of the missing values, and the goals of the analysis. Some methods are simple and straightforward, while others require more complex calculations and considerations. By understanding the different approaches to filling blank cells, data analysts and scientists can make informed decisions about how to handle missing data in their datasets.
The process of filling blank cells involves several steps, including identifying the missing values, determining the cause of the missingness, and selecting an appropriate method for filling the blank cells. This process can be time-consuming and labor-intensive, especially for large datasets. However, it is a critical step in ensuring the quality and reliability of the data. In the following sections, we will explore five common methods for filling blank cells, including their advantages, disadvantages, and applications.
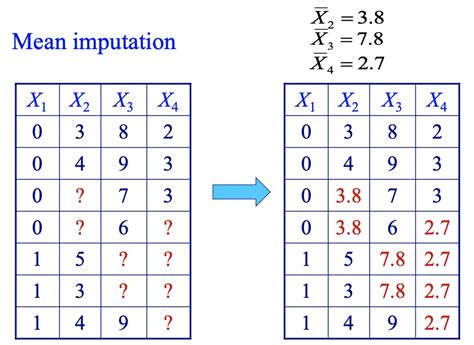
1. Mean/Median/Mode Imputation

Advantages and Disadvantages
The advantages of mean, median, and mode imputation include their simplicity and ease of implementation. These methods are also relatively fast and computationally efficient. However, they have several disadvantages. For example, they can introduce biases into the dataset, especially if the missing values are not missing at random. Additionally, these methods can reduce the variability of the data, leading to inaccurate conclusions.2. Regression Imputation
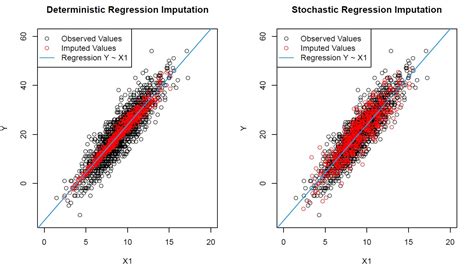
Advantages and Disadvantages
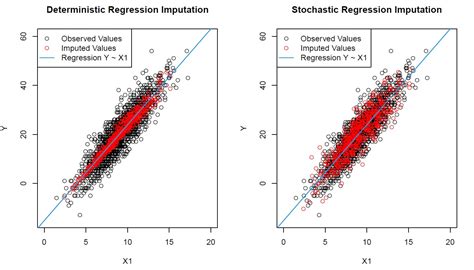
The advantages of regression imputation include its ability to capture complex relationships between variables and its flexibility in handling different types of data. However, this method has several disadvantages, including its complexity and computational intensity. Additionally, the quality of the imputed values depends on the accuracy of the regression model, which can be affected by various factors, such as the choice of variables and the model specification.3. K-Nearest Neighbors (KNN) Imputation
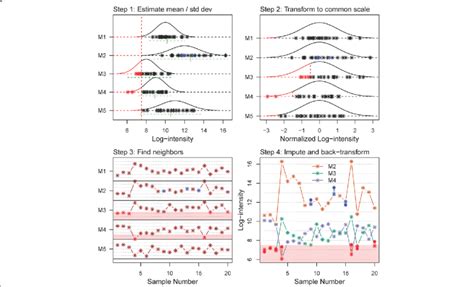
Advantages and Disadvantages
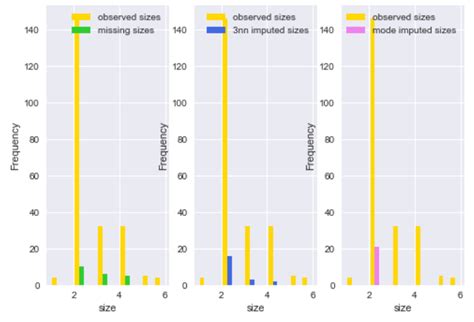
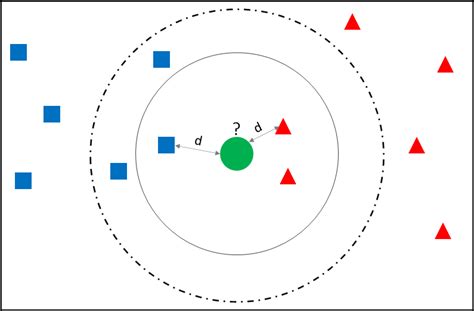
The advantages of KNN imputation include its ability to capture local patterns and relationships in the data. This method is also relatively simple to implement and computationally efficient. However, it has several disadvantages, including its sensitivity to the choice of k and the level of noise in the data. Additionally, KNN imputation can be affected by the curse of dimensionality, especially in high-dimensional datasets.4. Multiple Imputation
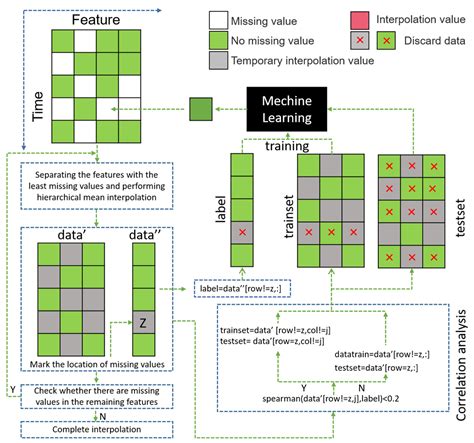
Advantages and Disadvantages
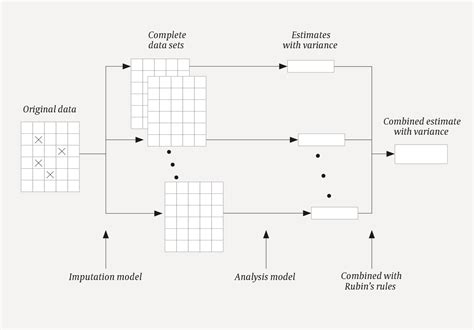
The advantages of multiple imputation include its ability to capture the uncertainty associated with the imputed values and its flexibility in handling different types of data. However, this method has several disadvantages, including its complexity and computational intensity. Additionally, the quality of the imputed values depends on the accuracy of the imputation model, which can be affected by various factors, such as the choice of variables and the model specification.5. Machine Learning-Based Imputation
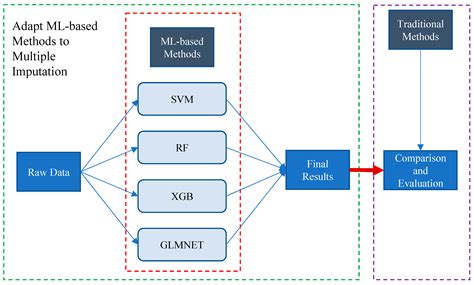
Advantages and Disadvantages
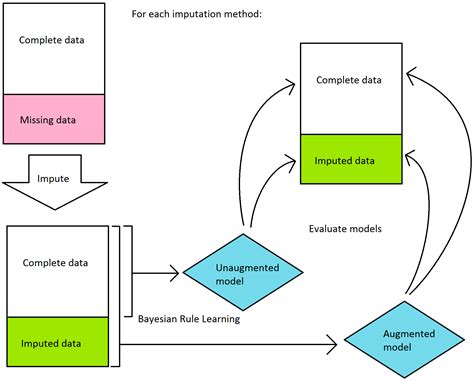
The advantages of machine learning-based imputation include its ability to capture complex patterns and relationships in the data. This method is also relatively flexible and can handle different types of data. However, it has several disadvantages, including its complexity and computational intensity. Additionally, the quality of the imputed values depends on the accuracy of the machine learning model, which can be affected by various factors, such as the choice of variables and the model specification.Imputation Methods Image Gallery
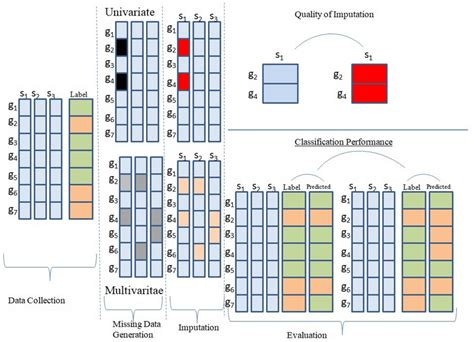
What is the best method for filling blank cells?
+The best method for filling blank cells depends on the nature of the data, the cause of the missing values, and the goals of the analysis. Some common methods include mean, median, and mode imputation, regression imputation, KNN imputation, multiple imputation, and machine learning-based imputation.
How do I choose the best imputation method for my dataset?
+The choice of imputation method depends on several factors, including the type of data, the level of missingness, and the relationships between variables. It is essential to explore different methods and evaluate their performance using metrics such as accuracy, precision, and recall.
What are the advantages and disadvantages of mean, median, and mode imputation?
+Mean, median, and mode imputation are simple and widely used methods for filling blank cells. The advantages of these methods include their simplicity and ease of implementation. However, they have several disadvantages, including their potential to introduce biases into the dataset and reduce the variability of the data.
In summary, filling blank cells is a critical step in data preprocessing that requires careful consideration and evaluation of different methods. The choice of method depends on the nature of the data, the cause of the missing values, and the goals of the analysis. By understanding the advantages and disadvantages of different imputation methods, data analysts and scientists can make informed decisions about how to handle missing data in their datasets. We encourage readers to share their experiences and insights on handling missing data and to explore different imputation methods to find the best approach for their specific use cases.