Intro
The issue of missing data is a common problem that many researchers, data analysts, and scientists face. It can occur due to various reasons such as non-response, equipment failure, or data entry errors. Missing data can lead to biased results, reduced accuracy, and incorrect conclusions. Therefore, it is essential to identify and address missing data to ensure the quality and reliability of the results. In this article, we will discuss five ways to find missing data and provide tips on how to handle it.
Missing data can have significant consequences on the outcome of a study or analysis. It can lead to incorrect conclusions, biased results, and reduced accuracy. Moreover, missing data can also affect the generalizability of the findings, making it challenging to apply the results to other contexts. Therefore, it is crucial to identify and address missing data to ensure the quality and reliability of the results.
The importance of finding missing data cannot be overstated. It is a critical step in data preprocessing and can significantly impact the outcome of a study or analysis. By identifying and addressing missing data, researchers and data analysts can ensure that their results are accurate, reliable, and generalizable. In this article, we will discuss five ways to find missing data and provide tips on how to handle it.
Understanding Missing Data

5 Ways to Find Missing Data
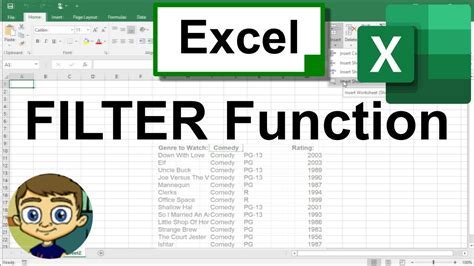
Using Data Visualization Techniques
Data visualization techniques such as plots and charts can be used to identify patterns and trends in the data. By visualizing the data, researchers and data analysts can identify missing values, outliers, and anomalies in the data. For example, a scatter plot can be used to identify relationships between variables, while a bar chart can be used to identify patterns in categorical data.Using Statistical Methods
Statistical methods such as mean, median, and mode can be used to identify outliers and anomalies in the data. By calculating summary statistics, researchers and data analysts can identify missing values and outliers in the data. For example, a mean can be used to identify the average value of a variable, while a median can be used to identify the middle value of a variable.Handling Missing Data

Using Listwise Deletion
Listwise deletion involves deleting cases with missing values. This method is simple and easy to implement but can result in biased estimates if the missing data is not missing completely at random. For example, if the missing data is related to the observed data, listwise deletion can result in biased estimates.Using Mean Imputation
Mean imputation involves replacing missing values with the mean of the variable. This method is simple and easy to implement but can result in biased estimates if the missing data is not missing completely at random. For example, if the missing data is related to the observed data, mean imputation can result in biased estimates.Best Practices for Handling Missing Data

Documenting the Missing Data
Documenting the missing data is essential to understand the patterns and trends in the data. By keeping a record of the missing data, researchers and data analysts can identify the number of missing values and the variables affected. This information can be used to develop an effective strategy to handle the missing data.Using Sensitivity Analysis
Sensitivity analysis involves analyzing the results to determine the impact of the missing data on the estimates. By analyzing the results, researchers and data analysts can determine the robustness of the estimates to the missing data. This information can be used to develop an effective strategy to handle the missing data.Missing Data Image Gallery








What is missing data?
+Missing data refers to the absence of values in a dataset. It can occur due to various reasons such as non-response, equipment failure, or data entry errors.
Why is it essential to handle missing data?
+Handling missing data is essential to ensure the quality and reliability of the results. Missing data can lead to biased estimates, reduced accuracy, and incorrect conclusions.
What are the types of missing data?
+There are three types of missing data: missing completely at random (MCAR), missing at random (MAR), and missing not at random (MNAR).
What are the strategies to handle missing data?
+There are several strategies to handle missing data, including listwise deletion, pairwise deletion, mean imputation, regression imputation, and multiple imputation.
What are the best practices for handling missing data?
+The best practices for handling missing data include documenting the missing data, analyzing the missing data, using multiple imputation, using sensitivity analysis, and using data validation.
In conclusion, finding and handling missing data is a critical step in data preprocessing. By understanding the types of missing data and using effective strategies to handle it, researchers and data analysts can ensure the quality and reliability of the results. We hope this article has provided valuable insights into the importance of finding and handling missing data. If you have any questions or comments, please do not hesitate to share them with us. We would be happy to hear from you and provide further guidance on this topic. Additionally, if you found this article helpful, please share it with your colleagues and friends who may benefit from it.