Intro
The importance of handling empty cells in data cannot be overstated. Empty cells can lead to errors, inconsistencies, and difficulties in data analysis. In many cases, empty cells are a result of missing data, which can occur due to various reasons such as non-response, data entry errors, or system glitches. It is crucial to replace empty cells with appropriate values to ensure the accuracy and reliability of data analysis. In this article, we will explore five ways to replace empty cells, providing a comprehensive guide on how to handle missing data effectively.
Replacing empty cells is a critical step in data preprocessing, as it helps to prevent errors and ensure that data analysis is accurate. There are various methods to replace empty cells, each with its own strengths and weaknesses. The choice of method depends on the nature of the data, the type of analysis being performed, and the level of missing data. By understanding the different methods available, data analysts can make informed decisions about how to handle missing data, ensuring that their analysis is reliable and accurate.
Handling empty cells is not just about replacing them with any value; it requires careful consideration of the data and the analysis being performed. Different methods are suitable for different types of data and analysis. For example, in statistical analysis, replacing empty cells with mean or median values may be appropriate, while in data mining, using imputation methods may be more effective. By understanding the different methods available and their applications, data analysts can ensure that they are using the most appropriate method for their specific use case.
Understanding Empty Cells
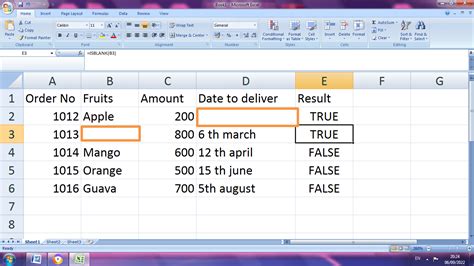
Causes of Empty Cells
Empty cells can occur due to various reasons, including non-response, data entry errors, system glitches, and data corruption. Non-response occurs when respondents fail to provide answers to certain questions or items, resulting in missing data. Data entry errors can occur when data is entered incorrectly or incompletely, leading to empty cells. System glitches can also cause empty cells, particularly when data is transferred or imported from one system to another. Data corruption can occur due to various factors, including hardware or software failures, resulting in empty cells.Method 1: Replacing with Mean or Median Values

Using mean or median values to replace empty cells has several advantages. It is a simple and straightforward method that can be easily implemented using most data analysis software. Additionally, it can help to maintain the distribution of the data, reducing the risk of biases and errors. However, this method also has some limitations. It can be sensitive to outliers, which can affect the accuracy of the mean or median values. Additionally, it may not be suitable for categorical data, where replacing empty cells with mean or median values may not be meaningful.
Advantages and Disadvantages
The advantages of using mean or median values to replace empty cells include simplicity, ease of implementation, and maintenance of data distribution. However, the disadvantages include sensitivity to outliers and limitations in categorical data.Method 2: Using Imputation Methods
Imputation methods have several advantages over other methods. They can help to maintain the relationships and patterns in the data, reducing the risk of biases and errors. Additionally, they can be used for both numerical and categorical data, making them a versatile option. However, imputation methods also have some limitations. They can be complex and require specialized software and expertise. Additionally, they may not be suitable for data with a high level of missingness, where the patterns and relationships in the data may be difficult to establish.
Types of Imputation Methods
There are various types of imputation methods available, including regression imputation, propensity score imputation, and multiple imputation. Each method has its own strengths and weaknesses, and the choice of method depends on the nature of the data and the level of missingness.Method 3: Using Interpolation Methods

Interpolation methods have several advantages. They can help to maintain the continuity and smoothness of the data, reducing the risk of biases and errors. Additionally, they can be used for both numerical and categorical data, making them a versatile option. However, interpolation methods also have some limitations. They can be sensitive to outliers, which can affect the accuracy of the interpolated values. Additionally, they may not be suitable for data with a high level of missingness, where the patterns and relationships in the data may be difficult to establish.
Advantages and Disadvantages
The advantages of using interpolation methods include maintenance of continuity and smoothness, versatility, and ease of implementation. However, the disadvantages include sensitivity to outliers and limitations in data with a high level of missingness.Method 4: Using Machine Learning Algorithms

Machine learning algorithms have several advantages. They can help to maintain the relationships and patterns in the data, reducing the risk of biases and errors. Additionally, they can be used for both numerical and categorical data, making them a versatile option. However, machine learning algorithms also have some limitations. They can be complex and require specialized software and expertise. Additionally, they may not be suitable for data with a high level of missingness, where the patterns and relationships in the data may be difficult to establish.
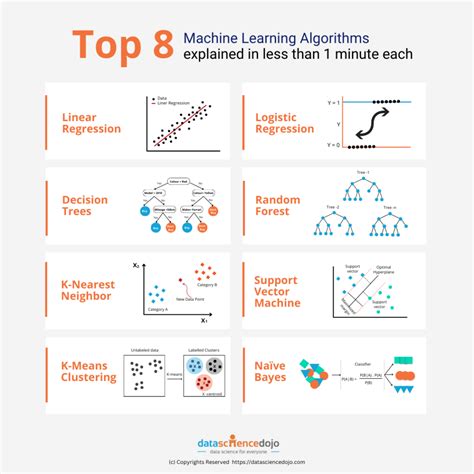
Types of Machine Learning Algorithms
There are various types of machine learning algorithms available, including decision trees, random forests, and neural networks. Each algorithm has its own strengths and weaknesses, and the choice of algorithm depends on the nature of the data and the level of missingness.Method 5: Using Data Augmentation Techniques
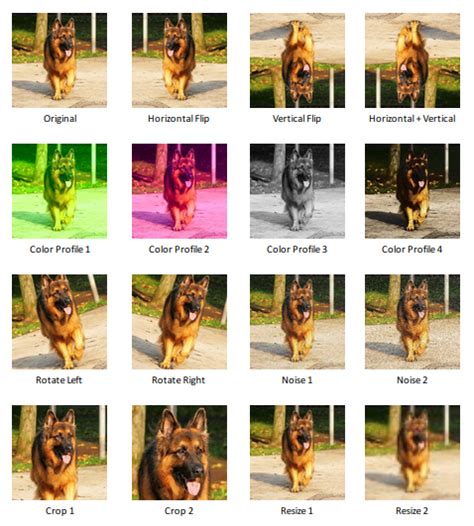
Data augmentation techniques have several advantages. They can help to increase the size of the dataset, reducing the risk of overfitting and improving the accuracy of the models. Additionally, they can be used for both numerical and categorical data, making them a versatile option. However, data augmentation techniques also have some limitations. They can be complex and require specialized software and expertise. Additionally, they may not be suitable for data with a high level of missingness, where the patterns and relationships in the data may be difficult to establish.
Advantages and Disadvantages
The advantages of using data augmentation techniques include increased dataset size, reduced overfitting, and improved model accuracy. However, the disadvantages include complexity, requirement for specialized software and expertise, and limitations in data with a high level of missingness.Empty Cells Image Gallery
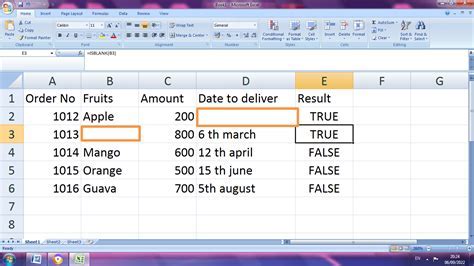

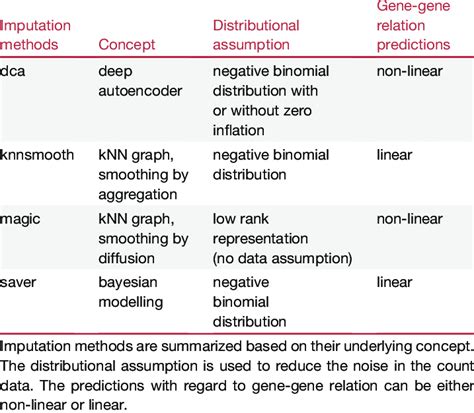

What are the causes of empty cells in data?
+Empty cells can occur due to various reasons, including non-response, data entry errors, system glitches, and data corruption.
What are the methods to replace empty cells?
+There are several methods to replace empty cells, including replacing with mean or median values, using imputation methods, using interpolation methods, using machine learning algorithms, and using data augmentation techniques.
What is the advantage of using imputation methods?
+Imputation methods can help to maintain the relationships and patterns in the data, reducing the risk of biases and errors.
What is the limitation of using interpolation methods?
+Interpolation methods can be sensitive to outliers, which can affect the accuracy of the interpolated values.
What is the advantage of using data augmentation techniques?
+Data augmentation techniques can help to increase the size of the dataset, reducing the risk of overfitting and improving the accuracy of the models.
We hope this article has provided you with a comprehensive guide on how to replace empty cells in data. Replacing empty cells is a critical step in data preprocessing, and it requires careful consideration of the data and the analysis being performed. By understanding the different methods available and their applications, data analysts can make informed decisions about how to handle missing data, ensuring that their analysis is reliable and accurate. If you have any questions or comments, please feel free to share them with us. We would be happy to hear from you and provide any further assistance you may need.