Intro
Discover 5 ways to extract the first word from text using programming techniques, including string manipulation, regex, and parsing, to improve data processing and text analysis skills with efficient word extraction methods.
The ability to extract the first word from a given text or string is a fundamental operation in text processing and natural language processing tasks. This operation can be useful in various applications, such as text analysis, information retrieval, and data preprocessing for machine learning models. There are multiple ways to achieve this, depending on the programming language or tools you are using. Here, we will explore five different methods to extract the first word from a string, focusing on Python as our primary programming language due to its simplicity and extensive use in text processing tasks.
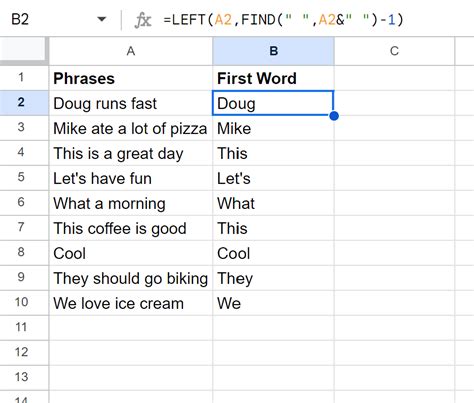
Extracting the first word can be as simple as splitting the string into words and taking the first element of the resulting list. However, the approach might slightly vary depending on the complexity of the string (e.g., presence of punctuation, leading or trailing whitespaces) and the specific requirements of your application (e.g., handling non-English characters, preserving case).
Introduction to Text Processing
Text processing involves manipulating and analyzing text data, which can include extracting specific parts of the text, such as the first word. This is a basic yet crucial step in many natural language processing (NLP) tasks, including sentiment analysis, topic modeling, and text classification.
Method 1: Using Split() Function
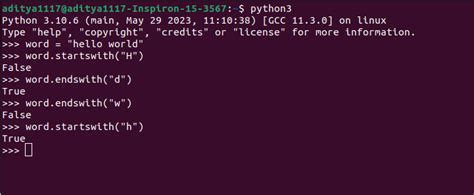
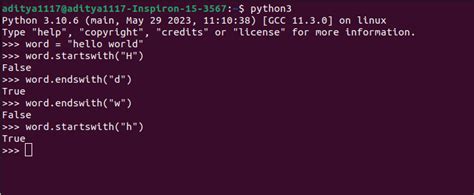
The most straightforward way to extract the first word from a string in Python is by using the split() function, which splits a string into a list where each word is a list item. You can then access the first element of this list to get the first word.
def extract_first_word(text):
words = text.split()
if len(words) > 0:
return words[0]
else:
return None
# Example usage
text = "This is an example sentence."
print(extract_first_word(text)) # Output: This
Method 2: Using Regular Expressions
Regular expressions (regex) provide a powerful way to search and manipulate text based on patterns. You can use regex to find the first word in a string by matching one or more word characters from the start of the string.
import re
def extract_first_word_regex(text):
match = re.match(r'\b\w+\b', text)
if match:
return match.group()
else:
return None
# Example usage
text = "Extracting the first word is useful."
print(extract_first_word_regex(text)) # Output: Extracting
Method 3: Handling Punctuation
Sometimes, the first word might be followed by punctuation, which you might want to remove. You can modify the split() method approach to remove leading punctuation.
import string
def extract_first_word_no_punct(text):
# Remove leading punctuation
text = text.lstrip(string.punctuation)
words = text.split()
if len(words) > 0:
return words[0]
else:
return None
# Example usage
text = ",This is another example."
print(extract_first_word_no_punct(text)) # Output: This
Method 4: Using NLTK Library
The Natural Language Toolkit (NLTK) is a comprehensive library used for NLP tasks. You can use NLTK to tokenize the text (split it into words or tokens) and then extract the first word.
import nltk
from nltk.tokenize import word_tokenize
nltk.download('punkt') # Download the Punkt tokenizer models
def extract_first_word_nltk(text):
tokens = word_tokenize(text)
if len(tokens) > 0:
return tokens[0]
else:
return None
# Example usage
text = "Tokenization is a key step in NLP."
print(extract_first_word_nltk(text)) # Output: Tokenization
Method 5: Manual Loop
For educational purposes or in specific scenarios where you cannot use built-in functions, you might want to extract the first word manually by looping through the characters in the string until you find the first space (indicating the end of the first word).
def extract_first_word_manual(text):
first_word = ""
for char in text:
if char.isspace():
break
first_word += char
return first_word if first_word else None
# Example usage
text = "Manually extracting the first word."
print(extract_first_word_manual(text)) # Output: Manually


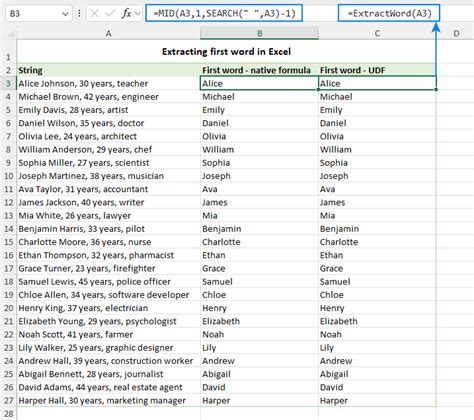

Gallery of First Word Extraction
First Word Extraction Image Gallery




What is the most common method for extracting the first word from a string in Python?
+The most common method is using the `split()` function, which splits the string into a list of words, and then accessing the first element of the list.
How do you handle punctuation when extracting the first word?
+You can handle punctuation by removing it before splitting the string into words. This can be done using the `lstrip()` method to remove leading punctuation or using regular expressions to match words without punctuation.
What is NLTK, and how is it used in text processing?
+NLTK (Natural Language Toolkit) is a library used for natural language processing tasks. It provides tools for tokenization, stemming, tagging, parsing, and semantic reasoning. In the context of extracting the first word, NLTK can be used for tokenization, which splits the text into words or tokens.
To summarize, extracting the first word from a string is a basic yet essential task in text processing and natural language processing. The approach can vary from simple string manipulation using the split() function to more complex methods involving regular expressions or libraries like NLTK. Each method has its use cases, depending on the specific requirements of your application, such as handling punctuation, non-English characters, or preserving case. By understanding and applying these methods, you can efficiently preprocess text data for various applications, including text analysis, machine learning, and information retrieval. Feel free to share your thoughts or ask questions about the methods discussed here, and don't forget to share this article with anyone who might find it useful.