Intro
The importance of identifying duplicates cannot be overstated, as it plays a crucial role in maintaining data quality, preventing errors, and ensuring the accuracy of information. In various fields, including business, research, and technology, duplicate identification is a vital process that helps to eliminate redundant data, reduce storage costs, and improve overall efficiency. With the increasing amount of data being generated every day, the need for effective duplicate identification methods has become more pressing than ever.
Identifying duplicates is a complex task that requires a combination of technical skills, attention to detail, and a thorough understanding of the data. It involves analyzing data sets, comparing records, and applying algorithms to detect similarities and differences. The process of duplicate identification is not only time-consuming but also requires significant resources, making it a challenging task for individuals and organizations. Despite these challenges, the benefits of identifying duplicates far outweigh the costs, as it helps to improve data quality, reduce errors, and increase productivity.
In recent years, the development of new technologies and algorithms has made it possible to identify duplicates more efficiently and effectively. Advanced data analytics tools, machine learning algorithms, and artificial intelligence techniques have enabled organizations to automate the duplicate identification process, reducing the need for manual intervention and minimizing the risk of human error. These technologies have also enabled organizations to analyze large datasets, identify patterns, and detect duplicates that may have gone unnoticed using traditional methods.
Introduction to Duplicate Identification

Duplicate identification is a critical process that involves analyzing data sets to detect and eliminate duplicate records. The process of duplicate identification is essential in various fields, including business, research, and technology, where data quality and accuracy are paramount. Duplicate identification helps to prevent errors, reduce storage costs, and improve overall efficiency. It also enables organizations to make informed decisions, improve customer relationships, and increase revenue.
Benefits of Duplicate Identification
The benefits of duplicate identification are numerous and well-documented. Some of the most significant advantages of duplicate identification include: * Improved data quality: Duplicate identification helps to eliminate redundant data, reducing errors and improving the overall quality of the data. * Reduced storage costs: By eliminating duplicate records, organizations can reduce storage costs and improve data management. * Increased efficiency: Duplicate identification helps to automate the data management process, reducing the need for manual intervention and minimizing the risk of human error. * Improved decision-making: Accurate and reliable data enables organizations to make informed decisions, improving customer relationships and increasing revenue.Formula to Identify Duplicates
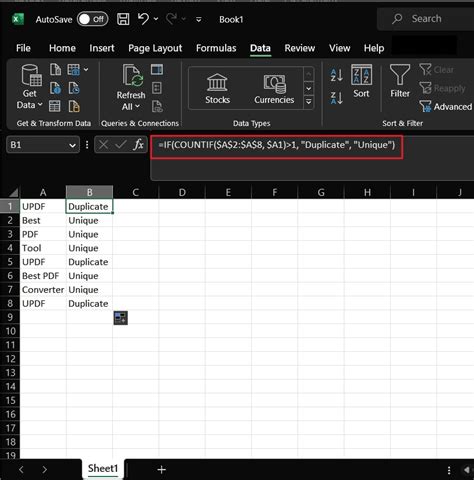
The formula to identify duplicates involves a combination of technical skills, attention to detail, and a thorough understanding of the data. The process of duplicate identification typically involves the following steps:
- Data collection: The first step in the duplicate identification process is to collect the data. This can involve gathering data from various sources, including databases, spreadsheets, and external data sources.
- Data cleaning: Once the data has been collected, it is essential to clean and preprocess the data. This involves removing any errors, inconsistencies, or missing values that may affect the accuracy of the duplicate identification process.
- Data comparison: The next step is to compare the data records to identify any duplicates. This can involve using algorithms, such as the Levenshtein distance algorithm or the Jaro-Winkler distance algorithm, to measure the similarity between the records.
- Duplicate detection: Once the data has been compared, the duplicate detection algorithm is applied to identify any duplicate records. This can involve using techniques, such as clustering or classification, to group similar records together.
Algorithms for Duplicate Identification
There are several algorithms that can be used for duplicate identification, including: * Levenshtein distance algorithm: This algorithm measures the number of single-character edits (insertions, deletions, or substitutions) required to change one word into another. * Jaro-Winkler distance algorithm: This algorithm measures the similarity between two strings based on the number of single-character edits required to change one string into another. * Cosine similarity algorithm: This algorithm measures the cosine of the angle between two vectors in a high-dimensional space. * K-means clustering algorithm: This algorithm groups similar records together based on their features and characteristics.Techniques for Duplicate Identification

There are several techniques that can be used for duplicate identification, including:
- Exact matching: This technique involves comparing the data records exactly, without any tolerance for errors or variations.
- Fuzzy matching: This technique involves comparing the data records using algorithms, such as the Levenshtein distance algorithm or the Jaro-Winkler distance algorithm, to measure the similarity between the records.
- Probabilistic matching: This technique involves using statistical models, such as Bayesian networks or decision trees, to predict the likelihood of a match between two records.
- Machine learning: This technique involves using machine learning algorithms, such as supervised or unsupervised learning, to identify patterns and relationships in the data.
Tools for Duplicate Identification
There are several tools that can be used for duplicate identification, including: * Data quality tools: These tools, such as Trifacta or Talend, help to clean, preprocess, and transform the data to improve its quality and accuracy. * Data integration tools: These tools, such as Informatica or Microsoft SQL Server Integration Services, help to integrate data from multiple sources and formats. * Data analytics tools: These tools, such as Tableau or Power BI, help to analyze and visualize the data to identify patterns and relationships. * Machine learning tools: These tools, such as scikit-learn or TensorFlow, help to build and train machine learning models to identify duplicates.Best Practices for Duplicate Identification
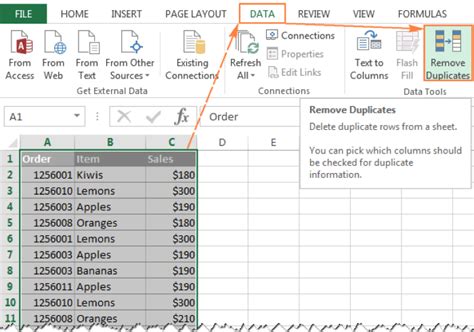
There are several best practices that can be followed for duplicate identification, including:
- Define the duplicate identification criteria: It is essential to define the criteria for duplicate identification, including the algorithms, techniques, and tools to be used.
- Use data quality tools: Data quality tools can help to clean, preprocess, and transform the data to improve its quality and accuracy.
- Use data integration tools: Data integration tools can help to integrate data from multiple sources and formats.
- Use machine learning tools: Machine learning tools can help to build and train machine learning models to identify duplicates.
- Monitor and evaluate the duplicate identification process: It is essential to monitor and evaluate the duplicate identification process to ensure its accuracy and effectiveness.
Challenges and Limitations of Duplicate Identification
There are several challenges and limitations of duplicate identification, including: * Data quality issues: Poor data quality can affect the accuracy and effectiveness of the duplicate identification process. * Data complexity: Complex data structures and formats can make it challenging to identify duplicates. * Scalability: Large datasets can make it challenging to identify duplicates, requiring significant resources and computational power. * Accuracy: The accuracy of the duplicate identification process can be affected by the algorithms, techniques, and tools used.Duplicate Identification Image Gallery








What is duplicate identification?
+Duplicate identification is the process of analyzing data sets to detect and eliminate duplicate records.
Why is duplicate identification important?
+Duplicate identification is important because it helps to improve data quality, reduce storage costs, and increase efficiency.
What are the challenges and limitations of duplicate identification?
+The challenges and limitations of duplicate identification include data quality issues, data complexity, scalability issues, and accuracy issues.
In conclusion, duplicate identification is a critical process that involves analyzing data sets to detect and eliminate duplicate records. The formula to identify duplicates involves a combination of technical skills, attention to detail, and a thorough understanding of the data. By following best practices, using data quality tools, and leveraging machine learning algorithms, organizations can improve the accuracy and effectiveness of the duplicate identification process. As data continues to grow in volume and complexity, the importance of duplicate identification will only continue to increase, making it essential for organizations to invest in this critical process. We invite you to share your thoughts and experiences with duplicate identification, and to explore the various tools and techniques available to help you improve your data quality and accuracy.