Intro
The importance of data matching cannot be overstated in today's digital age. With the exponential growth of data, organizations are constantly seeking ways to ensure that their data is accurate, up-to-date, and consistent across different systems and platforms. Data matching, also known as data reconciliation or data harmonization, is the process of identifying and matching similar data entities across different datasets or systems. This process is crucial for maintaining data quality, preventing data duplication, and ensuring that data is consistent and reliable. In this article, we will explore five ways to match data and discuss their benefits, challenges, and best practices.
Data matching is a critical process that has numerous applications in various industries, including finance, healthcare, marketing, and government. It helps organizations to identify and eliminate duplicate records, correct errors, and standardize data formats. By matching data, organizations can improve data quality, reduce data redundancy, and increase data consistency. This, in turn, can lead to better decision-making, improved customer service, and increased operational efficiency. With the increasing importance of data-driven decision-making, data matching has become an essential tool for organizations seeking to extract insights and value from their data.
The process of data matching involves several steps, including data preparation, data comparison, and data reconciliation. Data preparation involves cleaning, transforming, and formatting data to ensure that it is consistent and comparable. Data comparison involves using algorithms and techniques to identify matching records across different datasets. Data reconciliation involves reviewing and resolving any discrepancies or inconsistencies that arise during the matching process. There are various data matching techniques, including exact matching, fuzzy matching, and probabilistic matching. Each technique has its strengths and weaknesses, and the choice of technique depends on the specific use case and data characteristics.
Introduction to Data Matching

Data matching is a complex process that requires careful planning, execution, and monitoring. It involves using various techniques and algorithms to identify and match similar data entities across different datasets or systems. The goal of data matching is to ensure that data is accurate, up-to-date, and consistent across different systems and platforms. This is critical for maintaining data quality, preventing data duplication, and ensuring that data is consistent and reliable. By matching data, organizations can improve data quality, reduce data redundancy, and increase data consistency. This, in turn, can lead to better decision-making, improved customer service, and increased operational efficiency.
5 Ways to Match Data

There are several ways to match data, including exact matching, fuzzy matching, probabilistic matching, machine learning-based matching, and rule-based matching. Each technique has its strengths and weaknesses, and the choice of technique depends on the specific use case and data characteristics. Exact matching involves matching data entities based on exact values, such as names, addresses, or phone numbers. Fuzzy matching involves matching data entities based on similar values, such as names with typos or variations. Probabilistic matching involves matching data entities based on probability scores, such as matching names with similar sounds or spellings. Machine learning-based matching involves using machine learning algorithms to match data entities based on patterns and relationships. Rule-based matching involves matching data entities based on predefined rules and criteria.
Exact Matching
Exact matching is a simple and straightforward technique that involves matching data entities based on exact values. This technique is useful for matching data entities with unique identifiers, such as names, addresses, or phone numbers. Exact matching is fast and efficient but may not be effective for matching data entities with variations or errors. For example, exact matching may not match "John Smith" with "Jon Smith" or "John Smithe".Fuzzy Matching
Fuzzy matching is a technique that involves matching data entities based on similar values. This technique is useful for matching data entities with variations or errors, such as names with typos or variations. Fuzzy matching uses algorithms and techniques, such as Levenshtein distance or Jaro-Winkler distance, to measure the similarity between values. For example, fuzzy matching may match "John Smith" with "Jon Smith" or "John Smithe".Data Matching Techniques
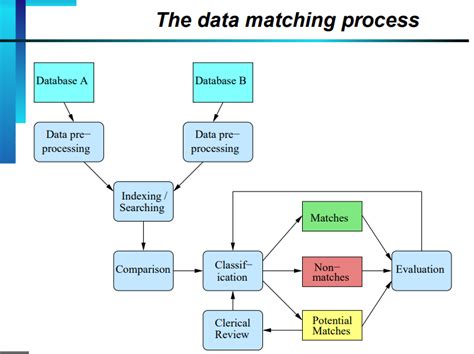
Data matching techniques are critical for ensuring that data is accurate, up-to-date, and consistent across different systems and platforms. There are various data matching techniques, including exact matching, fuzzy matching, probabilistic matching, machine learning-based matching, and rule-based matching. Each technique has its strengths and weaknesses, and the choice of technique depends on the specific use case and data characteristics. By using the right data matching technique, organizations can improve data quality, reduce data redundancy, and increase data consistency. This, in turn, can lead to better decision-making, improved customer service, and increased operational efficiency.
Probabilistic Matching
Probabilistic matching is a technique that involves matching data entities based on probability scores. This technique is useful for matching data entities with uncertain or incomplete information. Probabilistic matching uses algorithms and techniques, such as Bayesian inference or machine learning, to calculate the probability of a match. For example, probabilistic matching may match "John Smith" with "Jon Smith" based on the probability of a name variation.Machine Learning-Based Matching
Machine learning-based matching is a technique that involves using machine learning algorithms to match data entities based on patterns and relationships. This technique is useful for matching data entities with complex or nuanced relationships. Machine learning-based matching uses algorithms and techniques, such as neural networks or decision trees, to learn patterns and relationships in the data. For example, machine learning-based matching may match "John Smith" with "Jon Smith" based on the pattern of name variations in the data.Data Matching Best Practices

Data matching best practices are critical for ensuring that data is accurate, up-to-date, and consistent across different systems and platforms. There are several best practices for data matching, including data preparation, data comparison, and data reconciliation. Data preparation involves cleaning, transforming, and formatting data to ensure that it is consistent and comparable. Data comparison involves using algorithms and techniques to identify matching records across different datasets. Data reconciliation involves reviewing and resolving any discrepancies or inconsistencies that arise during the matching process. By following these best practices, organizations can improve data quality, reduce data redundancy, and increase data consistency.
Data Preparation
Data preparation is a critical step in the data matching process. It involves cleaning, transforming, and formatting data to ensure that it is consistent and comparable. Data preparation includes tasks, such as data cleansing, data standardization, and data normalization. Data cleansing involves removing errors, duplicates, and inconsistencies from the data. Data standardization involves converting data to a standard format, such as dates or names. Data normalization involves scaling data to a common range, such as 0 to 1.Data Comparison
Data comparison is a critical step in the data matching process. It involves using algorithms and techniques to identify matching records across different datasets. Data comparison includes tasks, such as exact matching, fuzzy matching, and probabilistic matching. Exact matching involves matching data entities based on exact values. Fuzzy matching involves matching data entities based on similar values. Probabilistic matching involves matching data entities based on probability scores.Data Matching Tools and Technologies
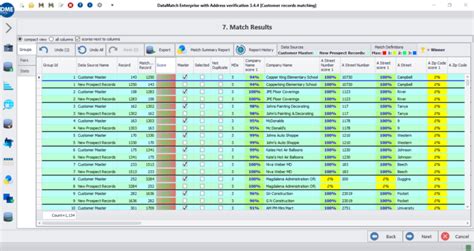
Data matching tools and technologies are critical for ensuring that data is accurate, up-to-date, and consistent across different systems and platforms. There are various data matching tools and technologies, including data matching software, data integration platforms, and cloud-based services. Data matching software includes tools, such as Talend, Informatica, and SAS. Data integration platforms include tools, such as Apache NiFi, Apache Beam, and AWS Glue. Cloud-based services include tools, such as Google Cloud Data Fusion, Amazon Web Services (AWS) Lake Formation, and Microsoft Azure Data Factory.
Data Matching Software
Data matching software is a critical tool for ensuring that data is accurate, up-to-date, and consistent across different systems and platforms. There are various data matching software tools, including Talend, Informatica, and SAS. These tools provide a range of features and functionalities, including data preparation, data comparison, and data reconciliation. Data matching software is useful for matching data entities across different datasets and systems.Data Integration Platforms
Data integration platforms are critical for ensuring that data is accurate, up-to-date, and consistent across different systems and platforms. There are various data integration platforms, including Apache NiFi, Apache Beam, and AWS Glue. These platforms provide a range of features and functionalities, including data ingestion, data processing, and data storage. Data integration platforms are useful for integrating data from different sources and systems.Data Matching Image Gallery

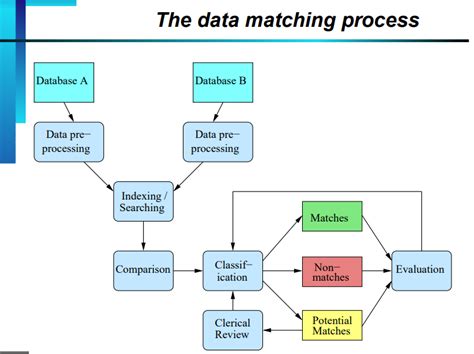



What is data matching?
+Data matching is the process of identifying and matching similar data entities across different datasets or systems.
Why is data matching important?
+Data matching is important for ensuring that data is accurate, up-to-date, and consistent across different systems and platforms.
What are the benefits of data matching?
+The benefits of data matching include improved data quality, reduced data redundancy, and increased data consistency.
What are the challenges of data matching?
+The challenges of data matching include data quality issues, data complexity, and data volume.
What is the future of data matching?
+The future of data matching includes the use of artificial intelligence, machine learning, and cloud-based technologies to improve data matching accuracy and efficiency.
In conclusion, data matching is a critical process that ensures data accuracy, consistency, and reliability across different systems and platforms. By using the right data matching techniques, tools, and technologies, organizations can improve data quality, reduce data redundancy, and increase data consistency. This, in turn, can lead to better decision-making, improved customer service, and increased operational efficiency. We encourage readers to share their experiences and insights on data matching and to explore the various resources and tools available for improving data matching accuracy and efficiency. By working together, we can unlock the full potential of data matching and drive business success in today's data-driven world.