Intro
Discover 5 ways to split names efficiently, including parsing, regex, and string manipulation, to improve data processing and name formatting with techniques like surname extraction and name normalization.
The importance of names cannot be overstated, as they serve as a fundamental aspect of our identity and play a crucial role in how we perceive and interact with one another. Names have been a cornerstone of human culture for centuries, with each one carrying its own unique history, significance, and cultural context. In today's digital age, the ability to manage and manipulate names has become increasingly important, particularly in the realm of data processing and analysis. One common challenge that arises when working with names is the need to split them into their constituent parts, such as first name, last name, and middle name. This process can be complex, especially when dealing with names from diverse cultural backgrounds. In this article, we will delve into the world of name splitting, exploring the various methods and techniques used to achieve this task.
The process of splitting names is not as straightforward as it may seem, as it requires a deep understanding of the nuances and complexities of names from different cultures. For instance, some cultures place the family name first, while others place it last. Additionally, some names may contain multiple parts, such as prefixes, suffixes, and titles, which can make the splitting process even more challenging. Despite these complexities, there are several approaches that can be used to split names effectively. These methods range from simple string manipulation techniques to more advanced machine learning algorithms. In the following sections, we will explore five ways to split names, highlighting the benefits and limitations of each approach.
Introduction to Name Splitting

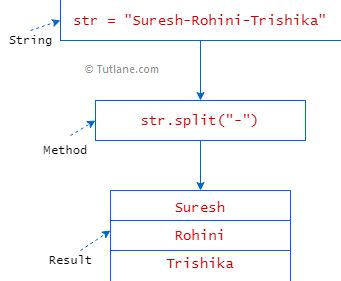
Method 1: Simple String Manipulation
Benefits and Limitations of Simple String Manipulation
The benefits of using simple string manipulation techniques for name splitting include: * Ease of implementation: This approach is relatively simple to implement, as it only requires basic programming skills. * Fast processing: Simple string manipulation algorithms can process names quickly, making them suitable for large datasets. However, there are also some limitations to this approach, including: * Limited accuracy: Simple string manipulation techniques can be limited in their ability to handle complex names or names with special characters. * Lack of flexibility: This approach can be inflexible, as it may not be able to adapt to different naming conventions or cultural contexts.Method 2: Regular Expressions
Benefits and Limitations of Regular Expressions
The benefits of using regular expressions for name splitting include: * Improved accuracy: Regular expressions can handle more complex names and naming conventions, making them more accurate than simple string manipulation techniques. * Flexibility: Regular expressions can be adapted to different cultural contexts and naming conventions, making them a more flexible approach. However, there are also some limitations to this approach, including: * Steeper learning curve: Regular expressions can be complex and require a significant amount of practice to master. * Slower processing: Regular expression algorithms can be slower than simple string manipulation algorithms, making them less suitable for large datasets.Method 3: Machine Learning Algorithms

Benefits and Limitations of Machine Learning Algorithms
The benefits of using machine learning algorithms for name splitting include: * High accuracy: Machine learning algorithms can learn to recognize complex patterns and nuances in names, making them highly accurate. * Adaptability: Machine learning algorithms can adapt to different cultural contexts and naming conventions, making them a flexible approach. However, there are also some limitations to this approach, including: * Requirement for large datasets: Machine learning algorithms require large datasets to train, which can be time-consuming and expensive to collect. * Computational resources: Machine learning algorithms require significant computational resources to train and deploy, which can be a limitation for some applications.Method 4: Rule-Based Systems
Benefits and Limitations of Rule-Based Systems
The benefits of using rule-based systems for name splitting include: * Ease of implementation: Rule-based systems can be relatively simple to implement, as they only require a set of predefined rules. * Fast processing: Rule-based systems can process names quickly, making them suitable for large datasets. However, there are also some limitations to this approach, including: * Limited flexibility: Rule-based systems can be inflexible, as they may not be able to adapt to different cultural contexts or naming conventions. * Limited accuracy: Rule-based systems can be limited in their ability to handle complex names or names with special characters.Method 5: Hybrid Approach
Benefits and Limitations of Hybrid Approach
The benefits of using a hybrid approach for name splitting include: * High accuracy: A hybrid approach can leverage the strengths of each method to achieve high accuracy. * Flexibility: A hybrid approach can adapt to different cultural contexts and naming conventions, making it a flexible approach. However, there are also some limitations to this approach, including: * Complexity: A hybrid approach can be complex to implement, as it requires integrating multiple methods. * Computational resources: A hybrid approach can require significant computational resources to train and deploy, which can be a limitation for some applications.Name Splitting Image Gallery
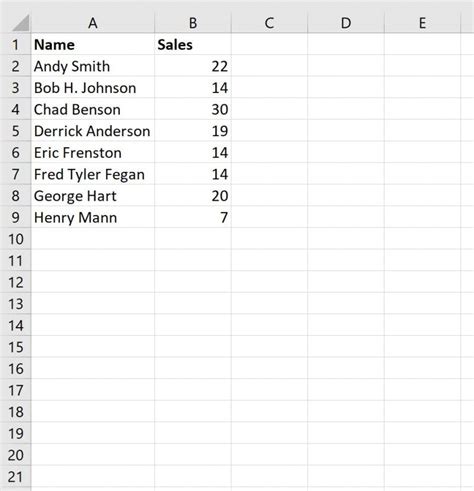
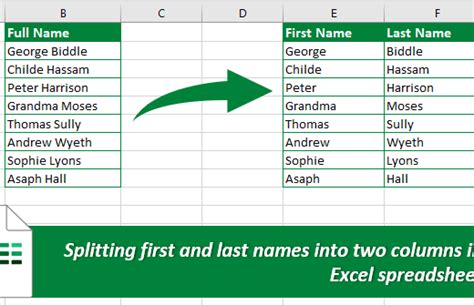
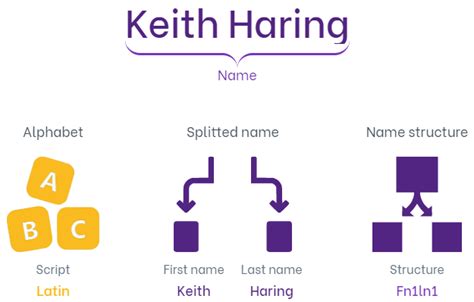
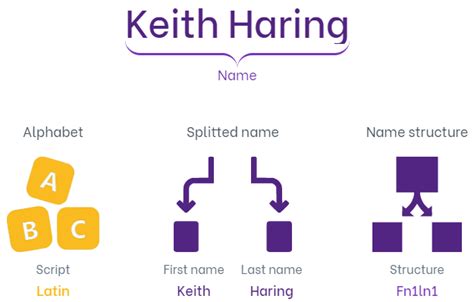
What is name splitting?
+Name splitting is the process of dividing a full name into its individual components, such as first name, last name, and middle name.
Why is name splitting important?
+Name splitting is important because it can help to improve the accuracy and quality of data, making it more reliable and useful for various purposes.
What are the different methods of name splitting?
+The different methods of name splitting include simple string manipulation, regular expressions, machine learning algorithms, rule-based systems, and hybrid approaches.
Which method is the most accurate?
+The most accurate method of name splitting depends on the specific use case and the characteristics of the data. However, machine learning algorithms and hybrid approaches can be highly effective in achieving high accuracy.
Can name splitting be used for non-English names?
+Yes, name splitting can be used for non-English names. However, it may require additional processing and adaptation to handle the unique characteristics and nuances of non-English names.
In conclusion, name splitting is a complex task that requires a deep understanding of the nuances and complexities of names from different cultures. The five methods of name splitting discussed in this article, including simple string manipulation, regular expressions, machine learning algorithms, rule-based systems, and hybrid approaches, each have their strengths and limitations. By choosing the right method or combination of methods, it is possible to achieve high accuracy and flexibility in name splitting, making it a valuable tool for various applications. We hope this article has provided you with a comprehensive understanding of the different methods of name splitting and their applications. If you have any further questions or would like to share your experiences with name splitting, please feel free to comment below. Additionally, if you found this article helpful, please share it with others who may benefit from this information.