Intro
Discover 5 ways K Means Clustering enhances data analysis with unsupervised learning, clustering algorithms, and machine learning techniques for efficient data grouping and pattern recognition.
The importance of data analysis in today's world cannot be overstated. With the exponential growth of data, businesses and organizations are looking for ways to make sense of it all. One technique that has gained popularity in recent years is K Means Clustering. This algorithm is a type of unsupervised learning, which means it can identify patterns and relationships in data without prior knowledge of the output. In this article, we will explore 5 ways K Means Clustering can be applied in real-world scenarios.
K Means Clustering is a versatile technique that can be used in various industries, from marketing and finance to healthcare and technology. Its ability to group similar data points together makes it an ideal tool for identifying trends, patterns, and correlations. Whether you're a data scientist, a business analyst, or simply someone interested in learning more about data analysis, this article will provide you with a comprehensive understanding of the applications of K Means Clustering.
The benefits of K Means Clustering are numerous. For one, it allows businesses to segment their customer base, creating targeted marketing campaigns and improving customer engagement. It can also be used to identify areas of improvement in operational efficiency, reducing costs and increasing productivity. Furthermore, K Means Clustering can be applied in predictive modeling, helping organizations forecast future trends and make informed decisions. With its many applications and benefits, it's no wonder K Means Clustering has become a staple in the world of data analysis.
Introduction to K Means Clustering
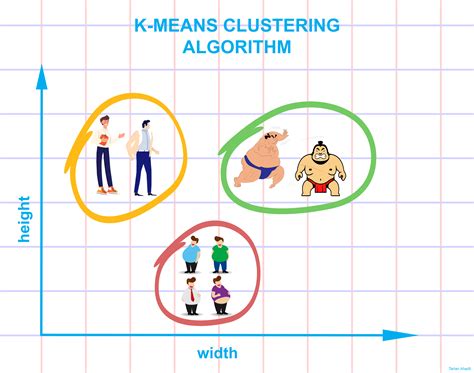
Applications of K Means Clustering
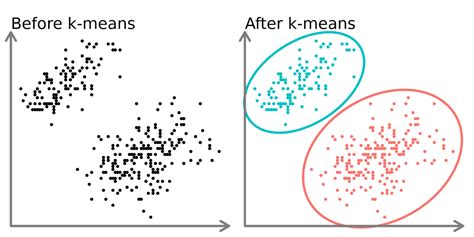
Customer Segmentation
Customer segmentation is one of the most common applications of K Means Clustering. By segmenting customers based on their demographics, behavior, and preferences, businesses can create targeted marketing campaigns and improve customer engagement. For example, a company that sells clothing can use K Means Clustering to segment its customers based on their age, gender, and purchase history.Image Segmentation
Image segmentation is another application of K Means Clustering. By segmenting images into different regions based on their pixel values, K Means Clustering can be used to identify objects, detect edges, and remove noise from images. For example, a company that specializes in medical imaging can use K Means Clustering to segment images of tumors and identify their boundaries.Benefits of K Means Clustering

Improved Customer Engagement
Improved customer engagement is one of the most significant benefits of K Means Clustering. By segmenting customers based on their demographics, behavior, and preferences, businesses can create targeted marketing campaigns and improve customer engagement. For example, a company that sells clothing can use K Means Clustering to segment its customers based on their age, gender, and purchase history, and then create targeted marketing campaigns to promote its products.Increased Operational Efficiency
Increased operational efficiency is another benefit of K Means Clustering. By identifying areas of improvement in operational efficiency, businesses can reduce costs and increase productivity. For example, a company that specializes in manufacturing can use K Means Clustering to identify areas of waste and inefficiency in its production process, and then implement changes to improve its operational efficiency.Common Challenges of K Means Clustering
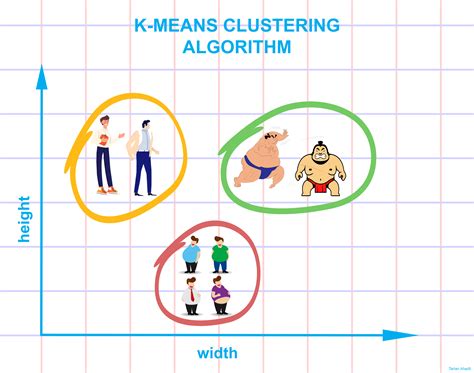
Choosing the Right Number of Clusters
Choosing the right number of clusters is one of the most significant challenges of K Means Clustering. If the number of clusters is too small, the algorithm may not be able to capture the underlying patterns in the data. If the number of clusters is too large, the algorithm may overfit the data. There are several methods that can be used to choose the right number of clusters, including the elbow method, the silhouette method, and the gap statistic method.Dealing with Outliers
Dealing with outliers is another challenge of K Means Clustering. Outliers can have a significant impact on the performance of the algorithm, and if they are not removed or handled properly, they can affect the accuracy of the clusters. There are several methods that can be used to deal with outliers, including removing them from the data, using a robust distance metric, and using a clustering algorithm that is robust to outliers.Best Practices for K Means Clustering
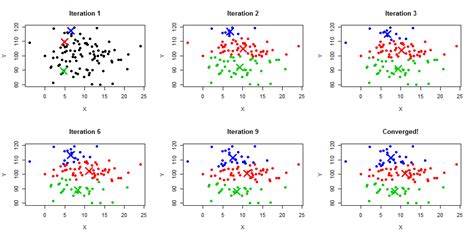
Choosing the Right Number of Clusters
Choosing the right number of clusters is critical to the performance of K Means Clustering. If the number of clusters is too small, the algorithm may not be able to capture the underlying patterns in the data. If the number of clusters is too large, the algorithm may overfit the data. There are several methods that can be used to choose the right number of clusters, including the elbow method, the silhouette method, and the gap statistic method.Dealing with Outliers
Dealing with outliers is critical to the performance of K Means Clustering. Outliers can have a significant impact on the performance of the algorithm, and if they are not removed or handled properly, they can affect the accuracy of the clusters. There are several methods that can be used to deal with outliers, including removing them from the data, using a robust distance metric, and using a clustering algorithm that is robust to outliers.K Means Clustering Image Gallery
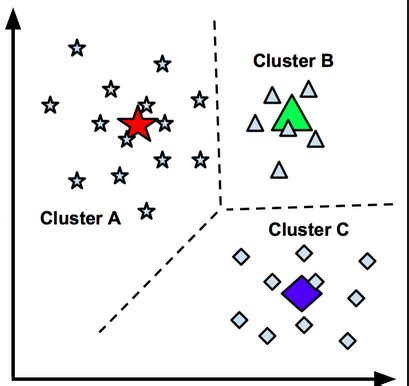
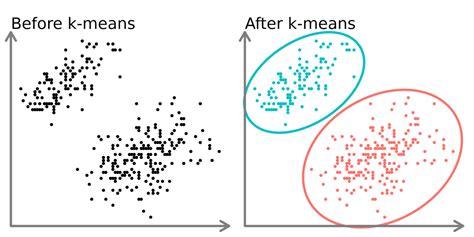
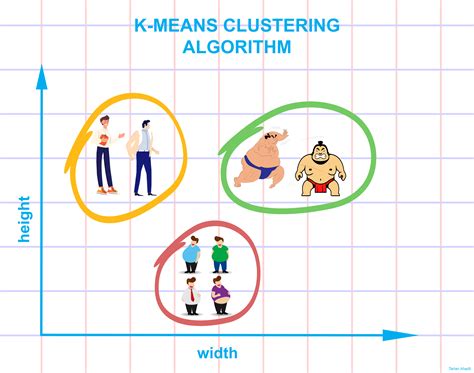

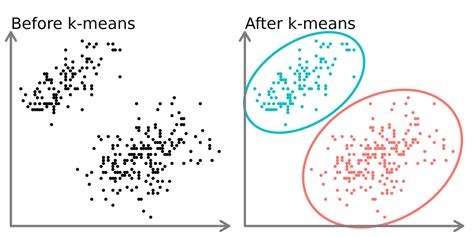
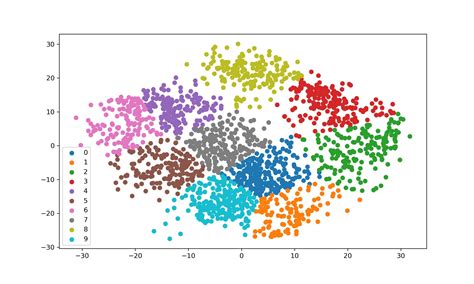
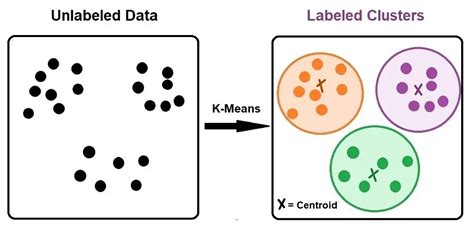
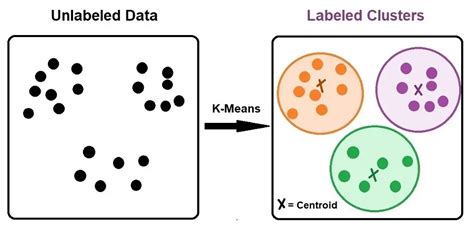
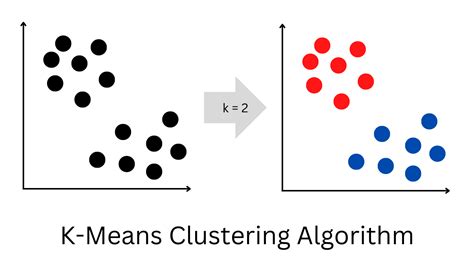
What is K Means Clustering?
+K Means Clustering is a type of unsupervised learning algorithm that groups similar data points into clusters based on their features.
What are the benefits of K Means Clustering?
+The benefits of K Means Clustering include improved customer engagement, increased operational efficiency, and better predictive modeling.
What are the challenges of K Means Clustering?
+The challenges of K Means Clustering include choosing the right number of clusters, dealing with outliers, and choosing the right initialization method.
What are the best practices for K Means Clustering?
+The best practices for K Means Clustering include choosing the right number of clusters, dealing with outliers, and choosing the right initialization method.
What are the real-world applications of K Means Clustering?
+The real-world applications of K Means Clustering include customer segmentation, image segmentation, gene expression analysis, and anomaly detection.
In conclusion, K Means Clustering is a powerful tool for data analysis that has a wide range of applications in various industries. Its ability to group similar data points together makes it an ideal tool for identifying trends, patterns, and correlations. By following the best practices for K Means Clustering and being aware of its challenges, businesses and organizations can unlock the full potential of this algorithm and gain valuable insights from their data. We encourage you to share your thoughts and experiences with K Means Clustering in the comments below, and to share this article with anyone who may be interested in learning more about this powerful algorithm.