Intro
Discover 5 ways to delete duplicates, removing duplicate files, contacts, and data effortlessly, and learn duplicate management techniques to optimize storage and productivity.
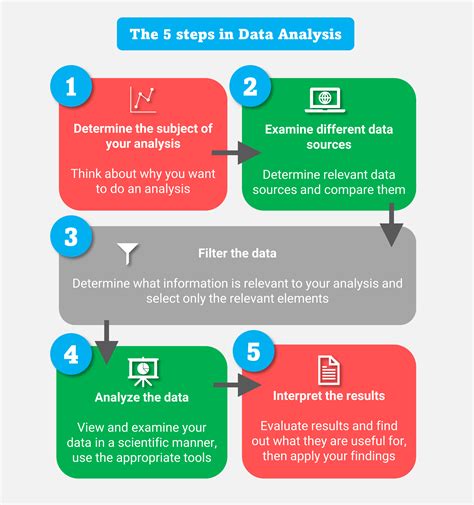
The presence of duplicate data in various forms of storage or databases can lead to inefficiencies, confusion, and inaccuracies. Whether it's in a spreadsheet, a database, or even a list of contacts, duplicates can occupy valuable space and hinder the effectiveness of data analysis and management. Deleting duplicates is a crucial step in data cleansing and organization, ensuring that data is accurate, reliable, and easy to manage. Here, we'll explore five ways to delete duplicates, making it easier for individuals and organizations to maintain clean and organized data sets.
Understanding the Importance of Deleting Duplicates
Method 1: Manual Removal

Steps for Manual Removal
- Sort the data to group similar entries together. - Go through the sorted data to identify duplicates. - Select and delete the duplicate entries.Method 2: Using Spreadsheet Functions

Using Conditional Formatting
Conditional formatting can also be used to highlight duplicate values, making them easier to identify and remove. By applying a rule that changes the fill color of cells containing duplicate values, users can quickly scan through their data and take action.Method 3: Database Queries
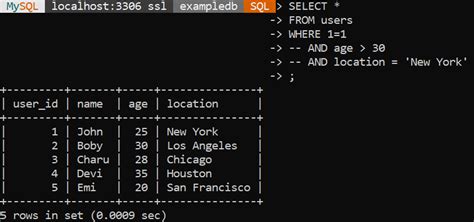
Example SQL Query
```sql DELETE FROM table_name WHERE rowid NOT IN ( SELECT MIN(rowid) FROM table_name GROUP BY column1, column2 ) ``` This query deletes rows from a table where the combination of `column1` and `column2` is duplicated, keeping only the row with the minimum `rowid`.Method 4: Using Third-Party Tools and Software

Benefits of Third-Party Tools
- Efficiency: Can handle large datasets quickly. - Accuracy: Minimizes the risk of human error. - Customization: Offers options for defining what constitutes a duplicate.Method 5: Programming Scripts

Example Python Script
```python import pandas as pdRead the data
df = pd.read_csv('data.csv')
Remove duplicates
df_clean = df.drop_duplicates()
Write the cleaned data to a new file
df_clean.to_csv('clean_data.csv', index=False)
This script reads a CSV file, removes duplicate rows based on all columns, and writes the result to a new CSV file.
Duplicate Removal Image Gallery







What are the consequences of not removing duplicates from a dataset?
+
The presence of duplicates can lead to inaccurate data analysis, wasted storage space, and decreased efficiency in data management. It can also lead to incorrect insights and potentially harmful decision-making.
How do I choose the best method for removing duplicates from my dataset?
+
The choice of method depends on the size of the dataset, the complexity of the data, and the tools available. For small datasets, manual removal might be sufficient, while larger datasets may require the use of spreadsheet functions, database queries, third-party tools, or programming scripts.
Can removing duplicates affect data integrity?
+
Removing duplicates, when done correctly, should improve data integrity by ensuring that each record is unique and accurate. However, if not done carefully, it can lead to the loss of important data. It's crucial to define what constitutes a duplicate accurately and to have a backup of the original data before making any changes.
In conclusion, deleting duplicates is a critical step in data management that can significantly improve the accuracy, reliability, and efficiency of data analysis and decision-making. By understanding the importance of removing duplicates and selecting the appropriate method based on the dataset's characteristics, individuals and organizations can ensure their data is clean, organized, and ready for effective use. Whether through manual removal, spreadsheet functions, database queries, third-party tools, or programming scripts, the removal of duplicates is an essential task in the era of big data. We invite readers to share their experiences and tips on managing duplicates in the comments below and to explore the resources provided for further learning on this topic.