Intro
Extract numbers efficiently with 5 proven methods, utilizing regex, data scraping, and text processing techniques to mine numerical data, parse digits, and perform quantitative analysis.
Extracting numbers from text can be a crucial task in various applications, such as data analysis, text processing, and information retrieval. The importance of extracting numbers lies in the ability to quantify and analyze data, make informed decisions, and gain valuable insights. In this article, we will delve into the world of number extraction, exploring its significance, benefits, and methods.
The ability to extract numbers from text has numerous applications in real-world scenarios. For instance, in financial analysis, extracting numbers from financial reports and statements can help analysts identify trends, predict market fluctuations, and make informed investment decisions. Similarly, in scientific research, extracting numbers from research papers and articles can facilitate the analysis of experimental results, identification of patterns, and validation of hypotheses.
As we navigate the complexities of number extraction, it becomes essential to understand the various methods and techniques employed in this process. From simple string manipulation to advanced machine learning algorithms, the approaches to extracting numbers from text are diverse and multifaceted. In this article, we will explore five ways to extract numbers, discussing their strengths, weaknesses, and applications.
Introduction to Number Extraction

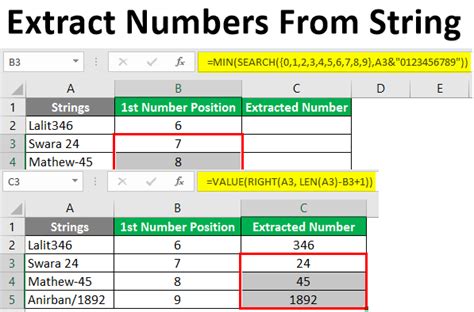
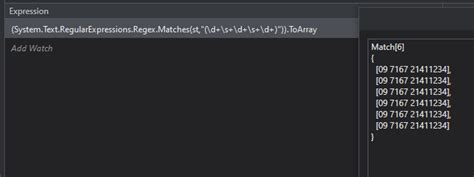
Method 1: Regular Expressions

Advantages and Disadvantages of Regular Expressions
The advantages of using regex for number extraction include: * High precision and accuracy * Flexibility in designing patterns to match specific formats * Efficient processing of large datasets However, the disadvantages include: * Steep learning curve due to complex syntax * Difficulty in handling unstructured or complex data * Potential for errors due to pattern mismatchesMethod 2: Natural Language Processing (NLP)
Advantages and Disadvantages of NLP
The advantages of using NLP for number extraction include: * Ability to handle unstructured and complex data * High accuracy and precision * Flexibility in adapting to different languages and formats However, the disadvantages include: * Complexity of NLP algorithms and models * Requirement for large amounts of training data * Potential for errors due to linguistic ambiguitiesMethod 3: Machine Learning
Advantages and Disadvantages of Machine Learning
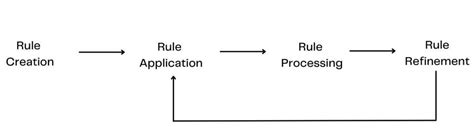
The advantages of using machine learning for number extraction include: * High accuracy and precision * Ability to handle large datasets * Flexibility in adapting to different formats and languages However, the disadvantages include: * Requirement for large amounts of training data * Complexity of machine learning algorithms and models * Potential for errors due to overfitting or underfittingMethod 4: Rule-Based Approach
Advantages and Disadvantages of Rule-Based Approach
The advantages of using a rule-based approach for number extraction include: * High precision and accuracy * Flexibility in designing rules to match specific formats * Efficient processing of large datasets However, the disadvantages include: * Difficulty in handling unstructured or complex data * Potential for errors due to rule mismatches * Requirement for manual rule design and maintenanceMethod 5: Hybrid Approach
Advantages and Disadvantages of Hybrid Approach
The advantages of using a hybrid approach for number extraction include: * High accuracy and precision * Ability to handle complex and diverse datasets * Flexibility in adapting to different formats and languages However, the disadvantages include: * Complexity of integrating multiple methods * Requirement for large amounts of training data * Potential for errors due to method mismatchesNumber Extraction Image Gallery


What is number extraction?
+Number extraction is the process of identifying and extracting numerical values from unstructured or semi-structured text data.
What are the applications of number extraction?
+Number extraction has numerous applications in real-world scenarios, including data analysis, text processing, and information retrieval.
What are the common methods used for number extraction?
+The common methods used for number extraction include regular expressions, natural language processing, machine learning, rule-based approach, and hybrid approach.
In conclusion, number extraction is a vital task in various applications, and the choice of method depends on the complexity and diversity of the dataset. By understanding the strengths and weaknesses of each method, we can develop effective strategies for extracting numbers from text, leading to improved data analysis, decision-making, and insights. We encourage readers to share their experiences and feedback on number extraction methods, and to explore the various tools and techniques available for this task.