Intro
Discover how to find missing values between columns using data analysis techniques, identifying gaps and inconsistencies with data matching, merging, and comparison methods.
Finding missing values between columns is a crucial task in data analysis, as it helps in identifying and handling inconsistencies in the data. This process is essential for ensuring the accuracy and reliability of the data, which in turn affects the outcomes of any analysis or modeling performed on the data. In this article, we will delve into the importance of finding missing values between columns, the methods used to identify them, and the steps to handle these missing values effectively.
When working with datasets, it's common to encounter missing or null values. These can arise due to various reasons such as data entry errors, equipment failures during data collection, or simply because the information was not available at the time of collection. Missing values can significantly impact the analysis, leading to biased results or errors in the models. Therefore, identifying and addressing these missing values is a critical step in the data preprocessing phase.
The importance of finding missing values between columns cannot be overstated. For instance, in a dataset containing customer information, if there are missing values in the columns related to customer demographics, it could lead to inaccurate segmentation and targeting. Similarly, in a medical dataset, missing values related to patient symptoms or treatment outcomes could compromise the reliability of the analysis, potentially leading to incorrect conclusions about the effectiveness of treatments.
Understanding Missing Values

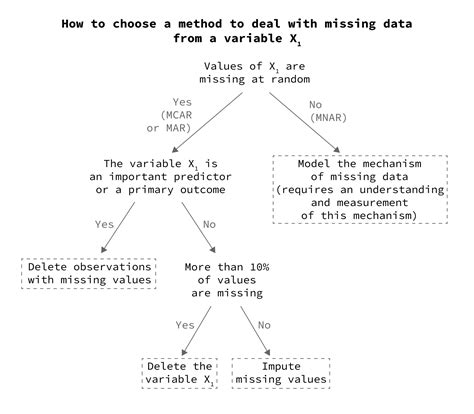
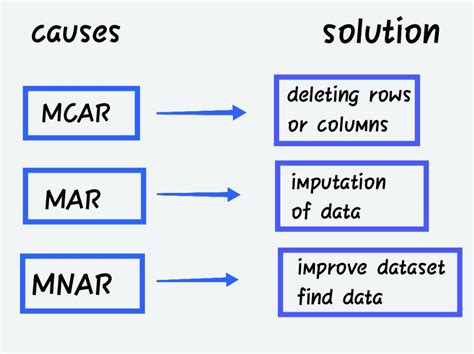
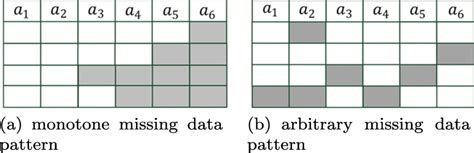
To effectively find and manage missing values, it's essential to understand the types of missing values and the context in which they occur. Missing values can be categorized into three types: Missing Completely At Random (MCAR), Missing At Random (MAR), and Missing Not At Random (MNAR). Each type requires a different approach for handling, making the identification step crucial for selecting the appropriate method.
Methods for Finding Missing Values
Several methods and tools are available for identifying missing values between columns. Statistical software and programming languages like R and Python offer built-in functions and libraries that can detect missing values. For example, in Python, the pandas library provides the isnull() function to identify missing values, while in R, the is.na() function serves a similar purpose. Additionally, data visualization techniques can be employed to visually inspect the data for missing values, providing a more intuitive understanding of the data's completeness.
Using Statistical Software
Statistical software packages such as SPSS, SAS, and Stata also offer functionalities for detecting missing values. These software packages often include procedures for identifying missing data patterns, which can be invaluable in understanding the nature of the missing values and in selecting an appropriate strategy for handling them.Data Visualization
Data visualization is another powerful tool for finding missing values. By creating plots and charts, analysts can visually identify patterns of missingness, including which variables are most affected and whether there are any relationships between missing values across different columns. Heatmaps and bar charts are particularly useful for this purpose, as they can clearly illustrate the distribution of missing values.Handling Missing Values

Once missing values have been identified, the next step is to decide on a strategy for handling them. The choice of method depends on the type of missing values, the amount of missing data, and the research question. Common strategies include listwise deletion, pairwise deletion, mean/median/mode imputation, regression imputation, and multiple imputation. Each method has its advantages and disadvantages, and the choice should be guided by the specific characteristics of the data and the goals of the analysis.
Listwise Deletion
Listwise deletion involves removing any case (row) that contains a missing value. This method is simple but can lead to significant data loss, especially if there are many missing values. It assumes that the data are Missing Completely At Random (MCAR), which may not always be the case.Mean/Median/Mode Imputation
Imputing missing values with the mean, median, or mode of the respective variable is another common approach. This method is straightforward and preserves the sample size but can underestimate the variability of the data and may not be appropriate if the data are not Missing At Random (MAR).Regression Imputation
Regression imputation involves using a regression model to predict the missing values based on other variables in the dataset. This method can provide more accurate imputations than mean/median/mode imputation but requires careful selection of predictor variables.Multiple Imputation
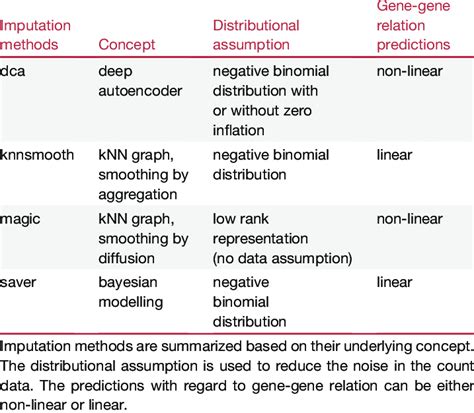
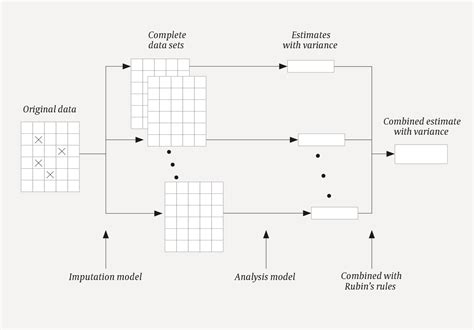
Multiple imputation is a more advanced technique that involves creating multiple versions of the dataset, each with different imputations for the missing values. This method is considered a gold standard for handling missing data, as it accounts for the uncertainty associated with the imputations. However, it can be computationally intensive and requires specialized software.Best Practices for Handling Missing Values

When handling missing values, several best practices should be kept in mind. First, it's essential to thoroughly document the process of identifying and handling missing values. This includes detailing the methods used for detection, the strategies employed for handling missing values, and any assumptions made about the nature of the missingness. Second, sensitivity analyses should be conducted to assess how different handling strategies affect the results. Finally, transparency about the presence and handling of missing values is crucial when reporting findings, as it allows readers to understand the potential limitations of the study.
Documentation
Documentation of the missing data handling process is critical for reproducibility and transparency. It should include descriptions of the missing data patterns, the rationale for the chosen handling strategy, and any challenges encountered during the process.Sensitivity Analyses
Conducting sensitivity analyses involves comparing the results obtained from different missing data handling strategies. This can help in understanding how robust the findings are to different assumptions about the missing values.Transparency
Transparency about missing data and how they were handled is essential for maintaining the integrity of the research. This includes reporting the amount of missing data, the methods used for handling missing values, and any limitations that the missing data may impose on the interpretations.Missing Values Image Gallery



What are the types of missing values in a dataset?
+Missing values can be categorized into three types: Missing Completely At Random (MCAR), Missing At Random (MAR), and Missing Not At Random (MNAR). Each type requires a different approach for handling.
How do I identify missing values in my dataset?
+You can identify missing values using statistical software or programming languages like R and Python, which offer built-in functions for detecting missing values. Data visualization techniques can also be employed to visually inspect the data for missing values.
What are the common methods for handling missing values?
+Common strategies for handling missing values include listwise deletion, pairwise deletion, mean/median/mode imputation, regression imputation, and multiple imputation. The choice of method depends on the type of missing values and the research question.
In conclusion, finding and handling missing values between columns is a critical step in data analysis. By understanding the importance of missing values, employing effective methods for detection, and selecting appropriate strategies for handling, analysts can ensure the accuracy and reliability of their data. Remember, the key to successful data analysis lies in meticulous data preparation, and handling missing values is a significant part of this process. We encourage you to share your experiences with missing data, ask questions, and explore the resources provided to deepen your understanding of this vital topic.