Intro
Removing duplicates from a dataset or a list is an essential task in various fields, including data science, programming, and data analysis. Duplicates can lead to inaccurate results, wasted resources, and decreased efficiency. In this article, we will explore five ways to remove duplicates, discussing the benefits, working mechanisms, and steps involved in each method.
The importance of removing duplicates cannot be overstated. In data science, duplicates can skew the results of statistical models, leading to incorrect conclusions. In programming, duplicates can cause errors and slow down the execution of code. In data analysis, duplicates can make it challenging to identify trends and patterns. Therefore, it is crucial to have effective methods for removing duplicates.
Removing duplicates is a critical step in data preprocessing, which is the process of cleaning and preparing data for analysis. Data preprocessing involves handling missing values, removing duplicates, and transforming data into a suitable format. By removing duplicates, we can ensure that our data is accurate, reliable, and efficient. In the following sections, we will delve into five ways to remove duplicates, providing detailed explanations, examples, and practical advice.
Method 1: Using Pandas DropDuplicates

To use drop_duplicates, we need to import the Pandas library, create a DataFrame, and then apply the drop_duplicates function. For example:
import pandas as pd
# Create a DataFrame
data = {'Name': ['Tom', 'Nick', 'John', 'Tom', 'John'],
'Age': [20, 21, 19, 20, 19]}
df = pd.DataFrame(data)
# Remove duplicates
df = df.drop_duplicates()
print(df)
This code will output:
Name Age
0 Tom 20
1 Nick 21
2 John 19
As we can see, the duplicates have been removed, and the resulting DataFrame only contains unique rows.
Method 2: Using SQL DISTINCT
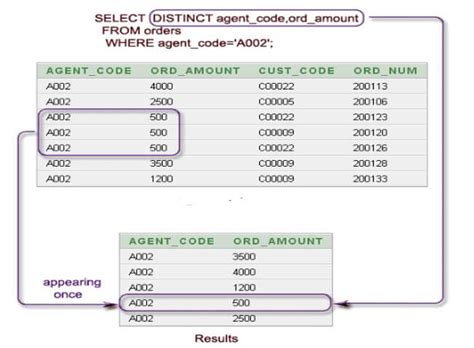
To use DISTINCT, we need to write a SQL query that includes the DISTINCT keyword. For example:
SELECT DISTINCT name, age
FROM customers;
This query will return a result set with only unique combinations of name and age.
Method 3: Using Python Set

To use a set, we need to convert the list or iterable to a set and then convert it back to a list. For example:
# Create a list
my_list = [1, 2, 2, 3, 4, 4, 5]
# Remove duplicates using a set
my_set = set(my_list)
my_list = list(my_set)
print(my_list)
This code will output:
[1, 2, 3, 4, 5]
As we can see, the duplicates have been removed, and the resulting list only contains unique elements.
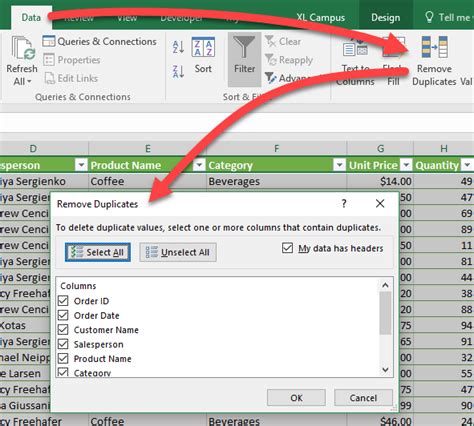
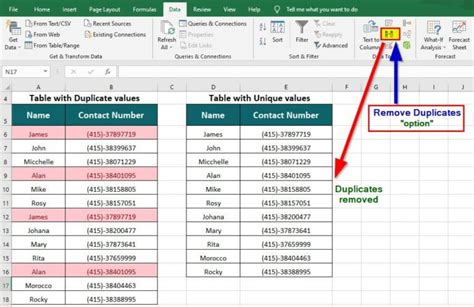
Method 4: Using Excel Remove Duplicates
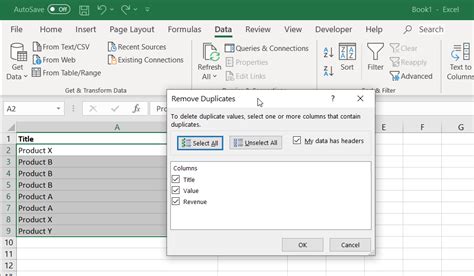
To use Remove Duplicates, we need to select the range of cells, go to the Data tab, and click on Remove Duplicates. We can then select the columns to consider when looking for duplicates and click OK.
Method 5: Using R Unique

To use unique, we need to create a vector or data frame and then apply the unique function. For example:
# Create a vector
my_vector = c(1, 2, 2, 3, 4, 4, 5)
# Remove duplicates using unique
my_vector = unique(my_vector)
print(my_vector)
This code will output:
[1] 1 2 3 4 5
As we can see, the duplicates have been removed, and the resulting vector only contains unique elements.
Remove Duplicates Image Gallery



What are duplicates in data?
+Duplicates in data refer to identical or nearly identical rows or records that appear multiple times in a dataset.
Why is it important to remove duplicates?
+Removing duplicates is important because it helps to ensure the accuracy and reliability of data, prevents errors, and improves the efficiency of data analysis and processing.
What are some common methods for removing duplicates?
+Some common methods for removing duplicates include using Pandas DropDuplicates, SQL DISTINCT, Python Set, Excel Remove Duplicates, and R Unique.
How do I choose the best method for removing duplicates?
+The best method for removing duplicates depends on the specific use case, the type of data, and the tools and software available. It's essential to consider factors such as data size, complexity, and the level of accuracy required.
Can I use multiple methods to remove duplicates?
+Yes, you can use multiple methods to remove duplicates, depending on the specific requirements of your project. For example, you might use Pandas DropDuplicates to remove duplicates from a DataFrame and then use SQL DISTINCT to remove duplicates from a database query.
In conclusion, removing duplicates is a critical step in data preprocessing, and there are various methods available to achieve this goal. By understanding the benefits and working mechanisms of each method, we can choose the best approach for our specific use case and ensure that our data is accurate, reliable, and efficient. Whether you're working with Pandas, SQL, Python, Excel, or R, there's a method available to help you remove duplicates and get the most out of your data. We encourage you to share your experiences, ask questions, and provide feedback on this topic. By working together, we can improve our data analysis skills and make better decisions with our data.