Intro
The world of data analysis is filled with various techniques and algorithms, each with its unique strengths and applications. Among these, clustering algorithms stand out for their ability to group similar data points into clusters, helping in pattern recognition, customer segmentation, and more. One of the most popular and widely used clustering algorithms is K-Means. This algorithm has been a cornerstone in data science and machine learning, offering a straightforward yet powerful method for identifying clusters within datasets. In this article, we will delve into the 5 ways K-Means clustering can be applied, exploring its benefits, working mechanisms, and practical examples.
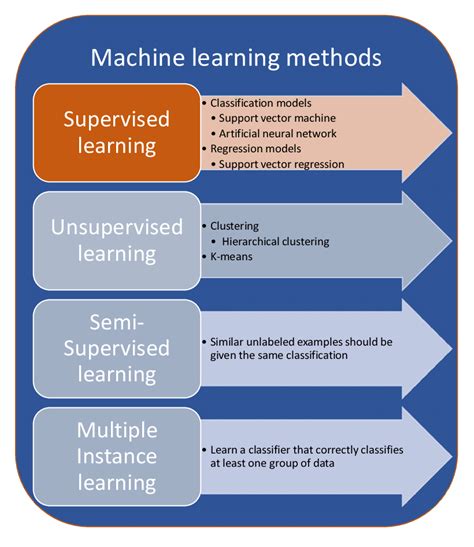
K-Means clustering is a type of unsupervised learning, which means it can identify patterns in data without prior knowledge of the output. The algorithm works by first initializing a specified number (K) of centroids randomly. Then, it iteratively updates the positions of these centroids and reassigns the data points to the closest centroid until a stopping criterion is met, such as no significant change in the centroids' positions or a predefined number of iterations. This process results in the formation of clusters around the centroids, with each cluster containing data points that are more similar to each other than to points in other clusters.
The versatility and simplicity of K-Means have led to its widespread adoption across various fields. Let's explore five significant ways K-Means clustering is applied:
Introduction to K-Means Clustering
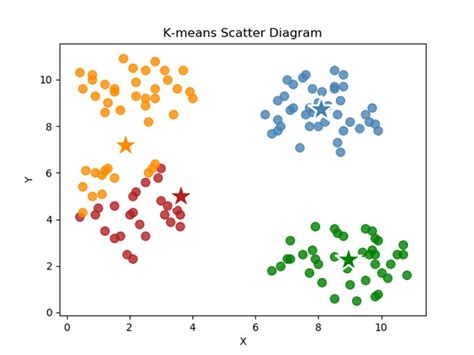
The algorithm's effectiveness in handling large datasets and its ability to be easily interpreted make it a favorite among data analysts. However, like any algorithm, K-Means has its limitations, including the need to specify the number of clusters (K) beforehand and sensitivity to initial centroid placements and outliers.
Customer Segmentation
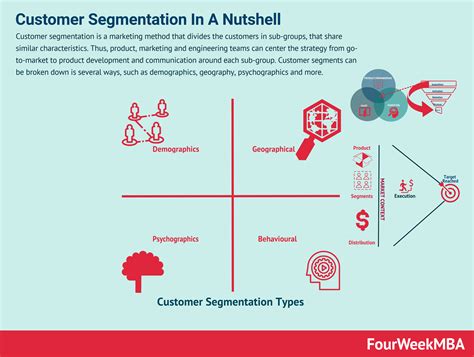
One of the most significant applications of K-Means clustering is in customer segmentation. By analyzing customer data such as purchase history, demographic information, and behavior, businesses can use K-Means to group customers into segments. These segments can then be targeted with tailored marketing strategies, improving the effectiveness of marketing campaigns and enhancing customer satisfaction. For instance, an e-commerce company might use K-Means to segment its customers based on their buying behavior, identifying high-value customers, frequent buyers, and customers who are at risk of churn.
Benefits of Customer Segmentation
- Personalized Marketing: Allows for targeted marketing efforts, increasing the likelihood of conversion.
- Resource Allocation: Helps in allocating resources more efficiently by focusing on high-value customer segments.
- Customer Retention: Identifies at-risk customers, enabling proactive measures to retain them.
Gene Expression Analysis
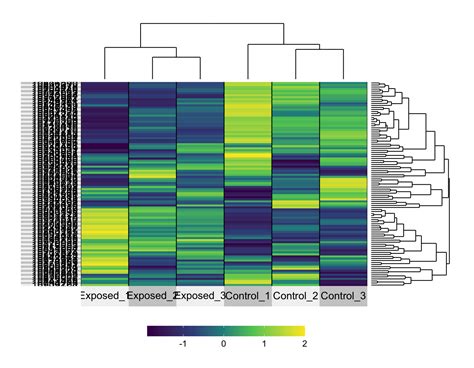
In the field of bioinformatics, K-Means clustering is used for analyzing gene expression data. This involves studying how genes are expressed under different conditions, which can provide insights into the functions of genes and their roles in diseases. By clustering genes based on their expression levels, researchers can identify co-regulated genes that may be involved in the same biological processes. This can lead to a better understanding of the genetic basis of diseases and the development of new therapeutic strategies.
Applications in Bioinformatics
- Disease Diagnosis: Helps in identifying genetic markers for diseases, facilitating early diagnosis.
- Drug Development: Aids in discovering new drug targets by understanding gene functions and interactions.
- Personalized Medicine: Enables tailored treatment plans based on an individual's genetic profile.
Image Segmentation

K-Means clustering can also be applied to image segmentation, where the goal is to divide an image into its constituent parts or objects. This is crucial in various applications such as object recognition, medical imaging, and satellite image analysis. By clustering pixels based on their color or texture, K-Means can help in separating the foreground from the background or identifying specific features within an image.
Applications in Image Processing
- Object Detection: Facilitates the detection of objects within images, useful in surveillance and autonomous vehicles.
- Medical Imaging: Helps in identifying tumors, fractures, and other abnormalities in medical images.
- Satellite Imaging: Aids in land use classification, change detection, and natural resource management.
Recommendation Systems
Recommendation systems are another area where K-Means clustering finds application. These systems suggest products or services to users based on their past behavior and preferences. By clustering users with similar preferences, K-Means can help in identifying patterns that are not immediately apparent, leading to more accurate recommendations. For example, an online streaming service might use K-Means to cluster users based on their viewing history, recommending movies or shows that are likely to interest them.
Benefits of Recommendation Systems
- Enhanced User Experience: Provides users with relevant content, increasing engagement and satisfaction.
- Increased Sales: Helps businesses by promoting products that are more likely to be purchased.
- Competitive Advantage: Offers a personalized experience, setting a business apart from its competitors.
Anomaly Detection
Lastly, K-Means clustering can be used for anomaly detection, which involves identifying data points that do not conform to the expected pattern. These anomalies could represent errors in data collection, unusual patterns of behavior, or potential security threats. By clustering data points and analyzing those that are farthest from their respective centroids, K-Means can help in detecting anomalies. This application is particularly useful in fraud detection, network security, and quality control.
Applications in Anomaly Detection
- Fraud Detection: Helps in identifying transactions that are likely to be fraudulent.
- Network Security: Aids in detecting intrusions and other security threats.
- Quality Control: Enables the detection of defects in manufacturing processes.
K-Means Clustering Image Gallery
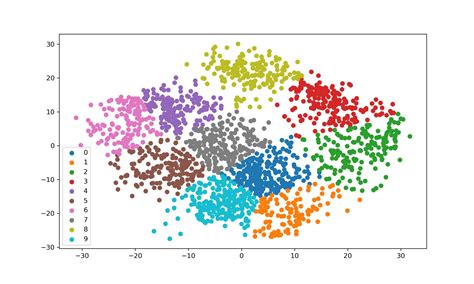
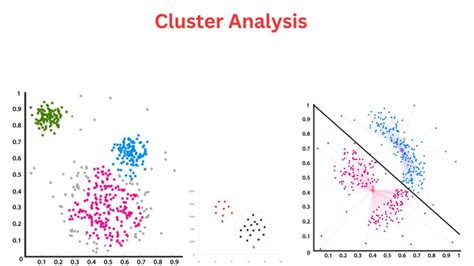

What is K-Means Clustering?
+K-Means clustering is a type of unsupervised learning algorithm used to identify clusters in the data based on their similarities.
How Does K-Means Clustering Work?
+K-Means works by initializing centroids, assigning data points to the closest centroid, and then updating the centroids based on the mean of the assigned points, repeating the process until convergence.
What Are the Applications of K-Means Clustering?
+K-Means clustering has various applications including customer segmentation, gene expression analysis, image segmentation, recommendation systems, and anomaly detection.
In conclusion, K-Means clustering is a versatile and powerful algorithm with a wide range of applications across different fields. Its ability to identify patterns and group similar data points into clusters makes it an indispensable tool in data analysis and machine learning. Whether it's enhancing customer experiences through personalized recommendations, advancing medical research through gene expression analysis, or improving image processing, K-Means clustering plays a significant role. As data continues to grow in volume and complexity, the importance of algorithms like K-Means will only continue to increase, making it a fundamental skill for anyone interested in data science and machine learning. We invite you to share your experiences and insights about K-Means clustering and its applications, and to explore how this algorithm can be used to drive innovation and solve real-world problems.